语音信号处理(五)声学回声消除
一、声学回声消除 简介
- 应用场景
- 语音通信场景:
在一般的通话场景中,如果能听到自己的回声,往往原因发生在“对端”,由于“对端”的回声抑制没有做好导致的 - 语音交互场景(打断场景)
如 对正在播放音乐的 智能音箱 说“切歌”- 在这种场景下,我们将扬声器端 叫做 远端信号或参考信号(far -end signal,reference signal),他是扬声器原始的音乐,没有没任何噪声污染 ;麦克可风 输入信号(实采信号,input signal) 包含了 近端信号 (near -end signal ),也是我们想识别的语音信号,此外还有其他信号比如噪声以及扬声器播放信号的干扰。
- AEC:的任务就是把在回声存在的前提下,怎么把近端语音信号提取出来。
- 语音通信场景:
AEC的基本原理:对消
- 如果能设计一组自适应滤波器,使得自适应滤波器,他的输出 刚好与麦克风接受的回声信号反向,那么只需将自适应的输出信号与接收信号相叠加即可消除回声信号。
二、 基本模块构成
- AEC 模块的输入有两个: 1、参考信号(远端信号),也即扬声器播放的纯净信号 2、麦克风接受信号
- AEC 使用的模块:
- 1、 时延估计模块(time delay estimation TDE) :任何自适应滤波器的时延追踪能力时有限的。
- 通过补偿的方式,让两路输入信号在时间上尽可能的对齐。从而为后续的自适应滤波器模块尽可能发挥跟踪学习的作用。
- 2、 回声消除模块:
- 主要是 自适应滤波器器模块
- 自适应滤波只能消除线性回声部分,所以,还有部分非线性回声(回声分量中有截幅)难以消除,所以通常还会在线性回声消除模块后面再追加一个 残余回声消除(抑制)模块
- 3、 双讲检测(double talk test DTT)
- 双讲检测 的目的就是告诉整个AEC 模块,应该处于 哪种 工作状态 。
- 一般认为,麦克风输入信号没有近端信号参与的时候收敛性能最好,能够迅速收敛到最佳状态,反之,当有近端信号时,收敛性能可能会变差
- 所以双讲检测的目的就是告诉 输入信号中是否存在近端信号,如果存在就不进行滤波器系数的更新,只用做简单的滤波器就好
- 4、残余回声抑制模块
- 见第二部分
- 1、 时延估计模块(time delay estimation TDE) :任何自适应滤波器的时延追踪能力时有限的。
2.1、时延估计模块
将麦克风信号 y(n) 和参考信号 x(n) 的时延调整到合适的范围。
时延估计的出发点是信号的相关性。
互相关法 CC
从公式中就可以知道如何估计回声的时延:先分别 麦克风信号与 参考信号的 DFT,相乘后 做傅里叶反变换,就能得到相关函数,求相关函数的最大值对应的 time index 就是我们要的时延。(也即互相关法,Cross Correlation)
广义互相关法 GCC
除此之外还有广义互相关法(Generalized Cross Correlation,GCC)
就是在互功率谱的基础上除去一个“模值”(也即幅度值),那么时延信息将只体现于相位上,而与幅度无关。即
$ P_{yx}(k)$为y(n)与x(n)的互功率谱密度
如果麦克风信号和参考信号的真实时延为$\tilde{m} $,那么理想情况下,互相关函数在$r_{xy}\{\tilde{m} \}$处取最大值。
这种互功率谱加权方式,称为GCC-PHAT(PHAse Transformation)相位变换加权互相关法,或CSP(Cross Spectral Phase)
之所以去掉幅度谱的信息,只保留相位谱的信息,就是因为我们认为延时信息主要体现于功率谱的相位上,而与幅度谱没有什么关系,时域上的延时对应的是频域上相位的移位。
这种操作也类似于白化操作,(白噪声有着非常好的性质,相关函数只有在零点有尖峰,但在其他地方(等价于时延)相关性就会非常的弱),这会方便我们求取相关函数的峰值。如果我们去除了功率谱幅度影响,其实就等价于对信号进行了白化的操作,对于这种广义互相关函数,他的峰值将会更加尖锐,这样在时域当中搜索峰值的时候会更加容易,不容易出错
扩展:在webrtc 当中,计算时延的方式虽然不是这种GCC方案,但是其思路还是相关,在wbrtc中采用的是一种非常简化的、能够加速方式、他将两路信号的相关采用一种 比特异或的方式来实现,会把两信号的功率谱做一个01的量化(如果在一个频点上的功率超过一定的门限就会将其量化为1,反之为0)……
2.2、线性回声消除
典的自适应滤波场景(子带) 有两种状态
状态一:FILTER 滤波模式
注意:采用频域自适应滤波时进行卷积运算的操作时,将采用博客上一节当讲到的 第二种形式的DFT,是一种扩展了窗函数,但是没有扩展W因子的DFT。
状态二:ADAPTION 自适应滤波模式
以NLMS为例
由于时子带自适应滤波,时域的结果可能是复数,故写成上式。
线性回声消除模块的状态机表示
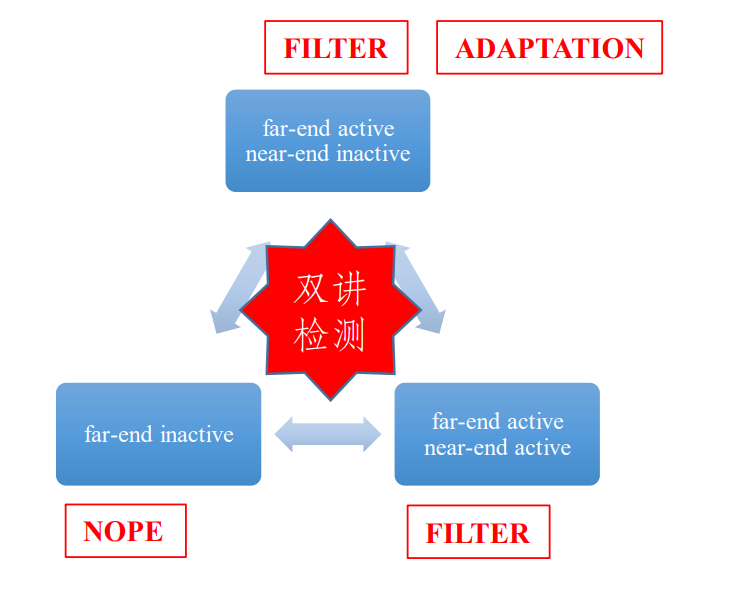
可以看到,控制状态转换的机制就是双讲检测
2.3、 双讲检测 Double Talk Test
判断是否有双讲状况(麦克风接受有是否有回音)存在
1、能量法
一般用类似回波损耗比(ERL,echo return loss)来表示
当永远没有 近端语音存在时(只有背景声、回声时),这个比值会趋于一个稳定的值,当存在 近端语音信号时,这个比例一般会变大
2、利用残余回声抑制的结果
2.4、 残余回声抑制 (Residual Echo Suppression,RES)
作用一:抑制残余回声
方法,采用NS的思路
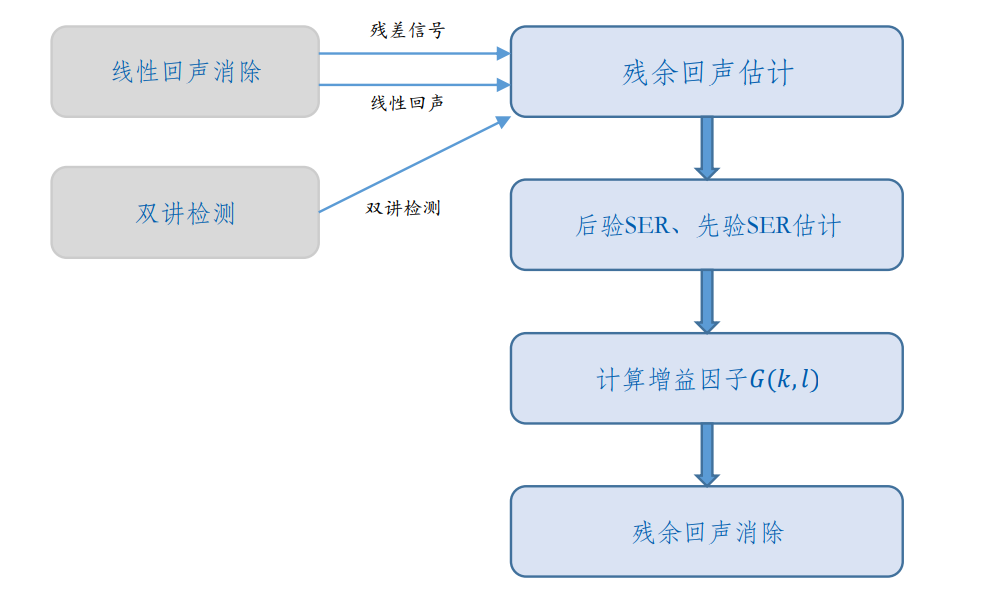
如图,本质上RES与NS流程基本一致,就是把残余回声(线性回声消除部分的残差视为噪声,信噪比换成了信号残差比SER)
在webrtc 当中,他的RES模块叫做 NLP(并非自然语言处理,而叫做非线性处理),基于维纳滤波的非线性处理
作用二:修正DTD
修正双讲检测结果的判决。
原理利用 (线性回声消除模块输出的)回声信号、残差信号、输入信号之间的“相关性”。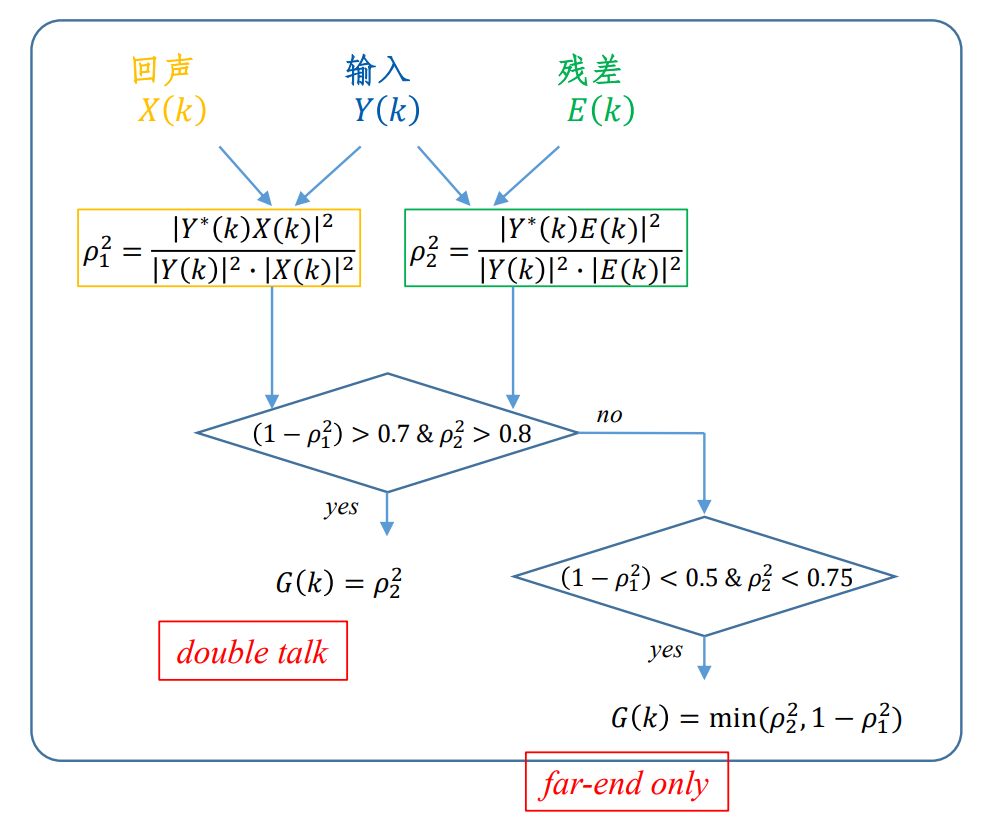
如图,如果回声信号与输入信号越 不相关,就代表这输入信号中包含 近端语音 的概率 比较大,因为,语音信号份量越大,这二者越不相关;同理如果输入信号与残差信号越相关 也代表输入信号中包含近端输入的可能越大(这是因为线性回声消除模块无法抑制近端输入信号)。
如果输入信号中回声与近端输入分量同时存在,就表明时双讲状态,这是,(RES模块的)增益因子就要取得保守一些,因为设置的过大就会影响线性回声抑制的结果。
反之,就是单讲状态,就是没有近端语音,只有回声部分。所以可以把RES模块的增益银子设置的更激进一些




