语音信号处理(八)端到端语音分离与目标说话人抽取
这一章 主要介绍近几年来 语音分离 技术路线 的分类
语音分离与目标说话人抽取的区别就是
- 输出侧:
语音分离是当有多个说话人时,会将每一个说话人的语音分别输出出来。而目标说话人抽取就是只将特定说话人(感兴趣的)的语音提取出来。 - 输入侧:
目标说话人抽取。输入测除了接收语音输入之外,还要接收目标说话人的声纹特征(参考信息)。
传统语音分离:非负矩阵分解、主成分分析
一、端到端语音分离基本框架
1.1、三段式的基本框架
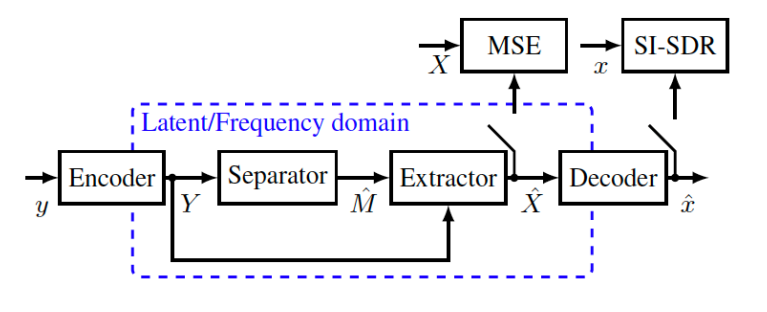
Encoder - Separator - Decoder (ESD框架)
Encoder
— 将输入信号从时域变换到另一个域(domain)或潜空间(latent space)中,在潜空间中完成语音分
离
注意:一般分为频域与时域的方案。频域(傅里叶变换等,或其他频域变换方式)是早些年比较常用的,近些年来多采用时域的方案,就是将混合的时域语音信号输入到一种网络当中,这个网络将时域信号变化为另外的域当中,这种域很难用显示的公式表达出来,我们及将其称为潜空间。Separator (+ Extractor)
— 在潜空间中,为每个独立声源估计mask;
这个mask 称为一种广义的mask,- 如果是频域,就是频域(幅度谱)的mask,就是有着明显物理意义的mask,比如说ideal mask 等等
- 如果是潜空间中的mask,其物理含义并不太明显
— 通过mask 和 语音的 变换域信号 做元素级别相乘,得到每个独立声源在潜空间中的估计
- Decoder:
— 将分离后的各个源信号反变换回到时域。
1.2、步骤
时域观测信号:
$s_i(t)$分别表示$C$个说话人各自的时域语音。
Encoder变换:
其中 k 为 frame index,L 为分析滤波器的长度,H 为 hop size,N 为分析滤波器个数。
这个公式代表了一种广义的变换措施。如果不能理解,可以带入简单的短时傅里叶变换来帮助理解。
Separator:
简单来说就是针对每一声源都估计一个mask, 吧所有的mask 放在一起就是一个mask network,
Extractor:
Decoder变换:
1.3、举例
- 举例:如果Encoder 与Decoder 是一种 人为设计好的变换 (handcrafted transformation )
如 将变换设定为傅里叶变换,将时域信号转换到频域 (如STFT)
对应的Encoder与Decoder的形式如下$h_a(t)$、$h_s(t)$分别是分析窗和综合窗。
之后Separator的操作就是利用机器学习来学习mask 。。。
- 举例:如果Encoder与Decoder不是一种设计好的、而是一种数据驱动的、需要学习的变换 learned transformation:
— 滤波器$u_n(t)$和$v_n(t)$的系数由网络自己学习,它们既可以与separator联合学习,也可以分别学习。
— 1-D CNN 是将时域信号变换到潜空间中的一个典型应用
1.4、基于time-frequency masking的分离方法 (频域)
优点:
- 与经典的信号处理算法(如频域波束形成,较为容易的可以嵌入到频域的框架当中)更好的相容
- mask具有较强的可解释性(interpretability) mask 直接对应于 频域谱 的 幅值(ideal mask) or 相位 (相位mask) 而变换到这种频域当中,语音信号具有稀疏性,也就是这种mask具有较强的可解释性和物理意义
缺点:
- STFT是一种通用的信号变换工具(特征),对于语音分离这一特定任务而言未必是最优的。好比与语音识别通常使用MFCC等特征,但是到其他任务当中就不行了
- 准确的相位重建比较困难;因为一般基于mask的方案只在幅度上估计,不会考虑相位,所以导致反变换时只用只有幅度变换时不够的
- 需要较高的频率分辨率(窗长需要足够大),所以延迟较大,不太适用于对实时性要求较高的场景
LOSS
- MSE
举例:
Deep Clustering 、 Deep attractor network、 u-PIT 、 Deep CASA 、Voice filter 、SpeakerBeam 、 SBF-MTSAL-Concat 、
1.5 基于 时域的分离的方法 TasNet
TasNet的优缺点几乎与频域方案完全相反
优点:
- 利用数据驱动的思想,让网络自己学习声音信号的声学特征表征,取代STFT,(利用一种一维的CNN来自己学习特征, 它解决了:既然不知道用什么样的特征更适合语音分离的任务,那不妨网络自己学习适合的特征)
- 无需显式地处理相位重建的问题;(因为这个网络通常就是实数域的变换,没有这种又傅里叶变换带来的相位问题)
- 短延时(如:2ms in Conv-TasNet, 2 samples in DPRNN-TasNet)
缺点:
- mask的可解释性较弱
- 不易与经典的信号处理算法相容 (与频域波数形成等算法难以相容)
Loss:
- SI-SDR
举例
TasNet、Conv-TasNet 、 Conditional-TasNet、 DPRNN-TasNet 、 SpEx 、SpEx+ 、Voice Separation 、LaFurca、Wavesplit 、 DPTNet、TasTas
1.6、SI-SDR 定义 (关于 评估语音分离的好坏)
见博客
PS: 基本上基于但麦克风的 都是采用 制度不变的SDR评估指标(SI-SDR ),但是对于 阵列麦克风就要注意。分离之后后接了一些波束形成,波束形成模块对于分离后的每一路信号的输出的尺度是有依赖的,如果在这种情况下,再用尺度不变的SDR 作为 任务的Target 就有些不合理了,这样 一般就采用标准的 SNR作为LOSS即可。
1.7、目标说话人抽取
所谓目标说话人抽取(Target Speaker Extraction),是指从一段混合语音当中抽取出特定说话人语音的分离技术
- “说话人相关”的分离任务;(一般要提取的语音 与参考信号语音来自一个声源)
- 不需要关注输出维度问题;(语音分离任务一般还要指定有多少个说话人(输出通路))
- 不需要关注排序问题 (与上面类似 输出排序)
- 输出一路信号,无需在多路信号中选择目标信号;(一般 向智能音箱 与要考虑 听哪一路说话人的)
- 代价:需要“参考信息”作为辅助(需要目标说话人的声纹 信息 )
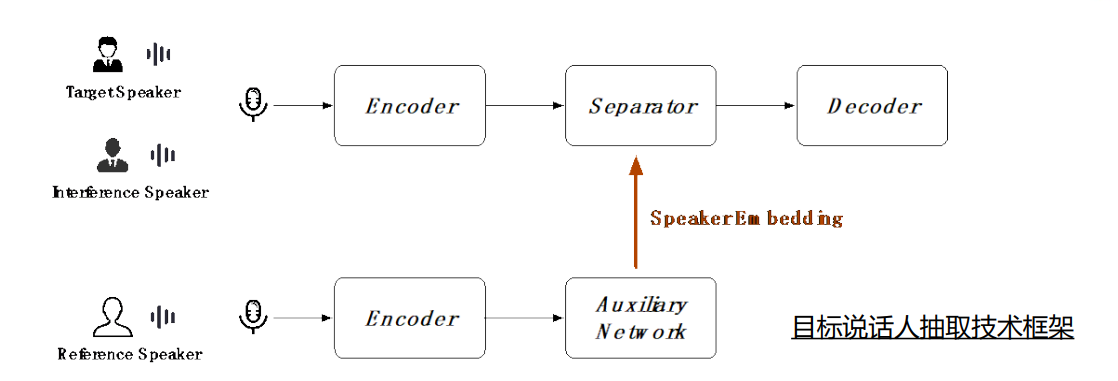
可以看到他在原来三段式的结构上增加了一个辅助网络,辅助网络可以提取出目标说话人的声纹信息 (Speaker Embedding)。
二、端到端的单通道语音分离
2.1 排序问题和输出维度问题
单目标(降噪): 很明显 无需考虑 维度 和 降噪问题
多目标:
- 排序问题: 需要考虑、怎样排序?
- 维度问题: 分离几个人的声音(需要先假设) 没多出一个通道都要改变网络结构
2.2 举例
2.2.1 语音分离:DPCL
Deep Clustering: A partition-learning method
本质上属于频域Mask的方法,但是他估算mask的方式是根据一种聚类网络来学习到的。是目前来说最早用深度学习来进行语音分离任务的方法。
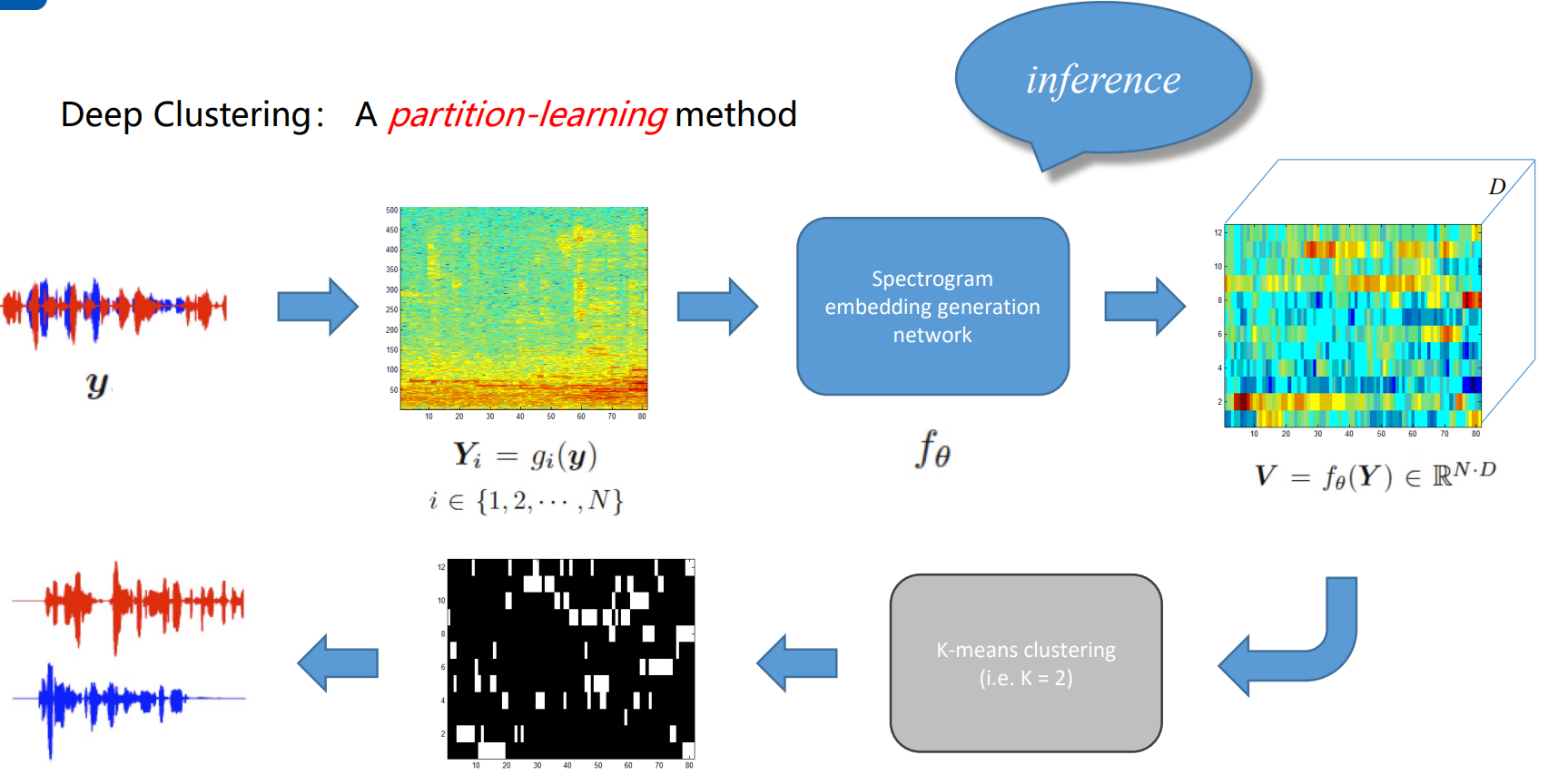
流程
- 首先把时域的语音信号转换到频域当中,
- 把其输入到 一个训练好的Spectrogram embedding generation network 当中,把输入从频域(时频域)变化到一种”embedding 域 “,从域上看,输入信号从一个二位的 时频谱变成了一个三维的谱。 这样可以到到一个效果,就是属于不同声源的embedding距离足够远,而属于同一个声源的embedding足够近
- 将这些embedding 利用kmeans网络聚类 得到 频域的mask 比如说分成两类,属于a语音的mask 是A,属于b语音的mask是B。
对于以上模型的关键就是如何训练的带这样的一个网络,能让同意说话人的频点对应的embedding举例足够近,不同说话人 足够远。
应采用Partition-based Training
— 寻找能够准确聚类的embedding的生成方式。
— 损失函数:$C(\theta)=||VV^T-YY^T||^2_W$
Y: labels
YY T: ideal affinity matrix
VV T: model’s affinity matrix
W: weighted F-norm
由于是基于聚类的语音分离算法,所以,一般即使具有不同数量的说话人时,这种算法也能可能通过聚类的方式推断输出维度应该是多少,缓解输出维度问题,但是对于排序问题不能解决。
2.2.2 语音分离:Permutation Invariant Training(PIT)置换不变训练
PIT解决了 语音分离任务的排序问题,它本质上是一种训练方式
其思想是:可所有可能的排序列出来,并把其中损失最小的排序作为输出排序。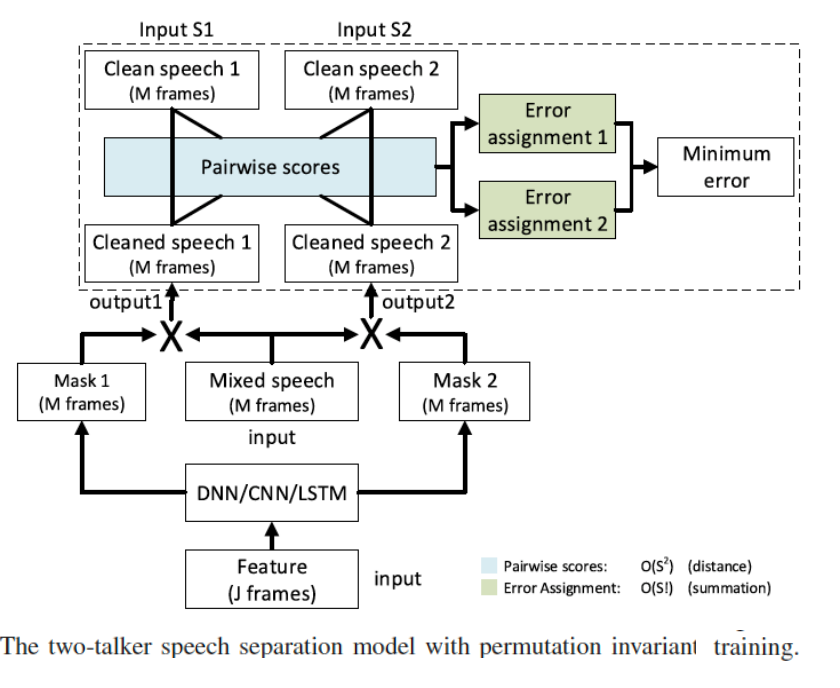
步骤
- 给定一个分离网络,为混合语音中的每个声源生成对应的mask;
- 穷举所有可能的排序(N!);
- label assignment: 使用loss最小的排序,更新分离网络
- 重复上述过程直至收敛;
- 可以解决排序问题,但无法解决输出维度问题。
2.2.3 语音分离:Deep CASA
来源于王德亮老师 Computational Auditory Scene Analysis (计算听觉场景分析,CASA)的框架
也是一种基于频域的语音分离技术。
CASA矿机主要分为两大步骤,Deep CASA 采用分而治之的思想将两大步骤分别用 深度网络 和 深度聚类网络来分别实现。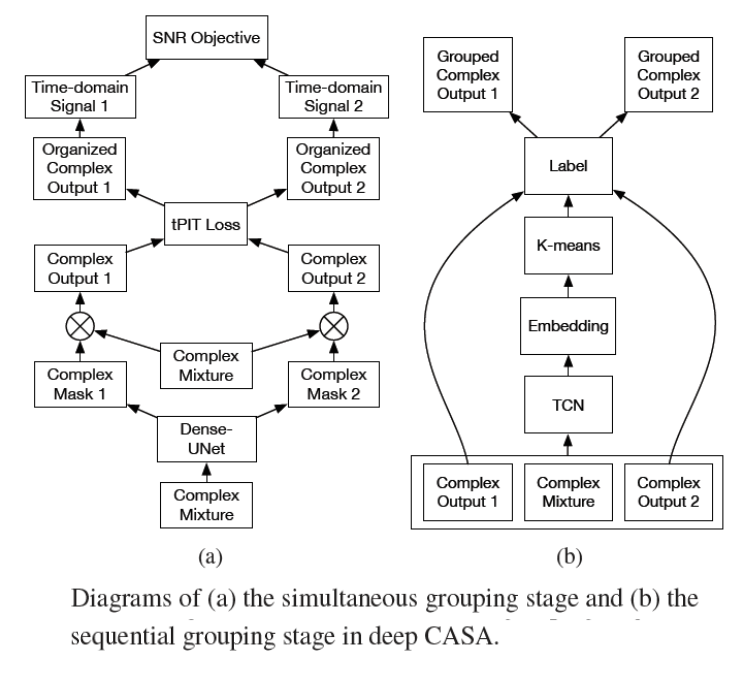
步骤一:Computational Auditory Scene Analysis
总体上:利用PIT实现帧级别分离,即分离出同一帧里分别属于不同声源的谱分量。
具体步骤(见图(a),从下往上看)
信号经过频域变换后(Complex Mixture),将其送入神经网络,假设只用分离两种语音,将为两种声源分别估计出两个Mask,将Mask于原来缓和语音的谱做点乘,就得到了每一个独立声源的输出。 然后再用PIT 选择最小Loss 的排序 并输出。并将最后的Loss 反过来训练用于分离的神经网络。
这个步骤其实完成的是帧级别的语音分离
步骤二:sequential grouping (序列追踪)
总体上类似聚类的方案
利用聚类网络实现每个独立说话人声源的追踪。训练规则类似DPCL,属于同一说话人的embedding距离尽可能接近,属于不同说话人的embedding距离尽可能远离。
具体步骤:
将 排序好的语音信号(上一个步骤得到的结果),和原来的混合语音谱 作为输入进TCN网络(TCN网络是 在时域语音分离中用的比较多), 用TCN网络产生 谱对应的 embedding,然后 embedding 通过一个K-means的聚类 得到分属于不同说话人的label(每一个label 对应着一个独立说话人的输出)。
2.2.4 、目标说话人抽取:Voice-Filter
早期的voicce filter 除了呼和语音输入,还需要 d-vector 输入(相当于一个声纹信息)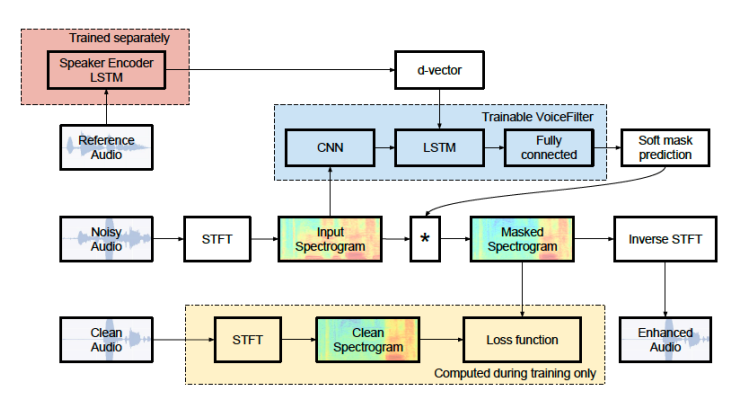
其分离网络(separator)是由 一个CNN 网络、一个双向的LSTM网络 以及一个全连接层 组成, 这样通过输入升温信息,只用输出特定说话人的信息
现在的voice filter ( VoiceFilter-Lite 2020)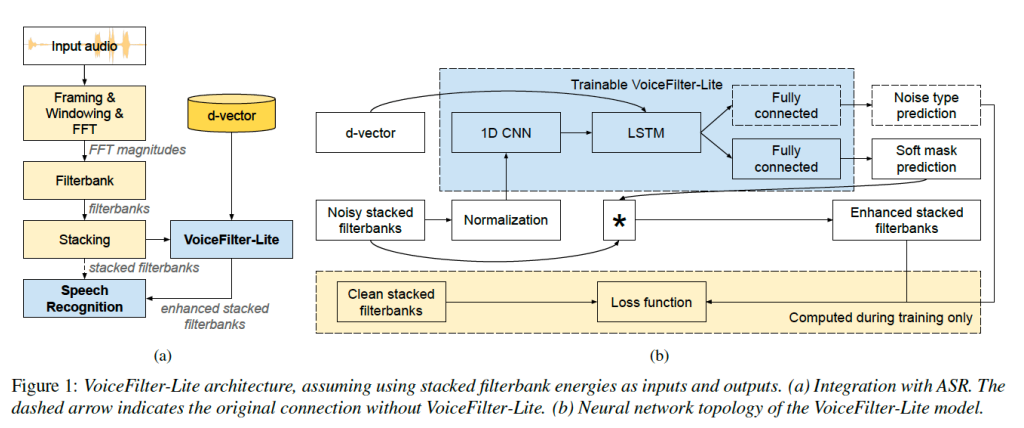
可以看到,他 直接在特征层面(Filter bank)完成的分离, 此外在Loss fuction 上面做了一个优化 避免了over -suppression的问题
— 面向ASR任务,无需重建信号波形;
— 输入:声学特征,e.g. stacked filterbank energies;
— 输出:增强特征;
— 避免over-suppression问题(保证输出不会有太大的失真)
$L_{asym}=\sum_t \sum_f \left( g_{asym}(S_{cln}(t,f)-S_{enh}(t,f),a)\right)^2$
2.2.5、语音分离(时域):Tasnet
上面基本上是基于 频域的 语音分离技术,现在技术而言,基于时域的语音分离技术他在割裂数据集上的性能提升方面显得更强一些,TasNet开启了基于时域语音分离技术的先河。
由罗毅博士Yi Luo,提出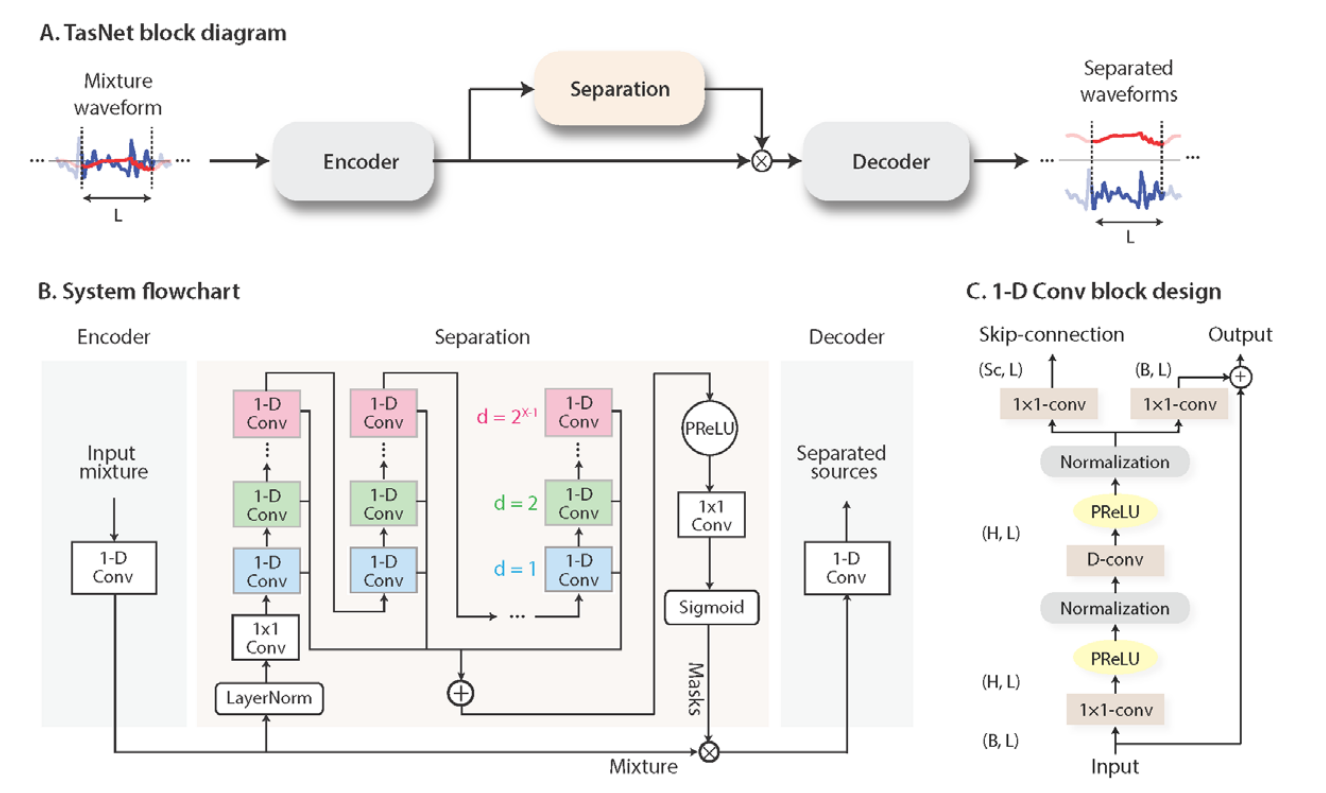
可以看到它明显是一个三段式结构
encoder 与 decoder 都是一种 一维卷积的变换网络
中间的网路结构是一种 TCN 的结构, TCN 本质上是一种膨胀式 的CNN (感受野,增加?),估算出Mask 与潜空间的混合语音普做元素级别的相乘。
在Conv-TasNet 之后又出现了类似的 改进版本,如Dual-Path RNN-TasNet(DP RNN TasNet)如下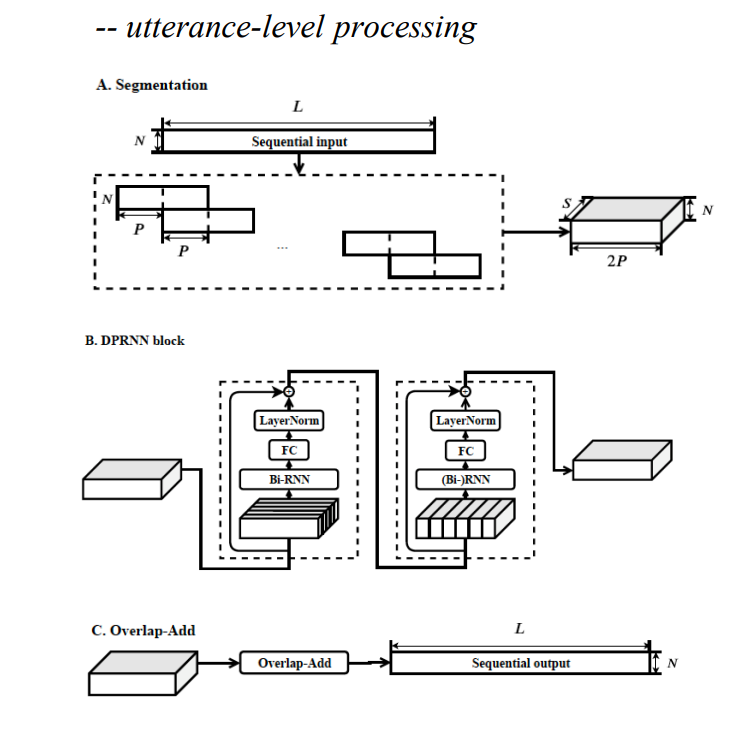
相对于Conv-TasNet,其Encoder与DeCoder都没有变化,变化的只有Separator,使用的upassRNN? 用两组RNN来实现 introRNN interRNN (块间RNN,块内部的RNN ) 感受野比TasNetRNN
之后又出现了Multi-Path RNN-TasNet
考虑了句子间的关联, 感受野进一步增大
2.2.6 目标说话人抽取 (时域):SpEx & SpEx+
SpEx
参考信号通过Speaker Encoder 网络(辅助网络)输入,作为Speaker Embedding 提取的方式,然把Speaker Embedding 嵌入到每一层 tcn上,变成一种抽取的结构
SpEx+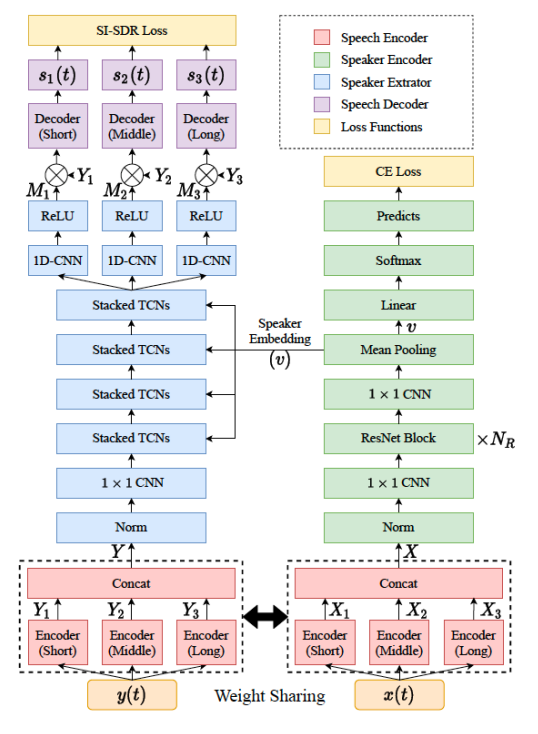
SpEx+ 相对于SpEx的改进就是,原来的SpEx 混合语音输入的“Encoder”网络与参考语音的“Encoder”网络结构是不同的的,SpEx+ 将他们两个做成了结构一样的网络结构
2.3、 语音分离技术路线 总结
按照 Separator、Encoder/Decoder、Training mechanisim、 usage of spkr-embedding 分类
Separator

最早的Separator 使用 双向的LSTM做的,encoder、decoder 通常是傅里叶变换,整体以上是一个基于频域的语音分离框架
TasNet 将Separator 转变成了TCN,而将encoder decoder 变成1D-CNN
随后为了扩大分离器的感受野,是他能感受、更加长时的语音特征(增大感受野),将中间的TCN换成了DPRNN,或者是MPRNN
也有打破这种三段式结构的,如U-net、WaveNet
U-Net最早用于音乐分离(如分离伴奏和人声)网络,它是一种U型的网络,左半边可以看作是一种广义的Encoder,右半边视为Decoder ,是一种 wave-form to wave-form 的网络结构。
WaveNet 最早用于语音合成领域
Encoder/Decoder
大致可以分为三类,重点关注$u_n(t)$
固定滤波器 Fixed filters : STFT, mel filterbank, gammatone filterbank,
自由滤波器 Free filters : all weights are jointly or separately learned.
嵌入到Separator 与其共同学习得到 如TasNet
- 参数化滤波器(介于上面二者之间) Parameterized filters : a family of filters whose parameters are learned with the network.
如三角滤波器组,如果给出中心频率就可以算出三角滤波器组的所有系数,所以只需要学习一些关键参数即可不用学习滤波器所有参数
现在的一些试验机过表明对于 Encoder与Decoder 用一位卷积网络,或者更多维的卷积网络来生成,也许效果回更好,而且;两边不一定要对称;
此外也可以采用更多尺度(scale)的encoder,如 Separator 中为了 获得更大的感受野,用了块内、块见、句子见、等不同维度的 RNN 一样,encoder也可以采用这种方式。所谓尺度简单来说就是窗长。
Training mechanism 训练机制
两步训练法Two-step training
思路是encoder与decoder先单独训练、之后再单独训练中间的Separator
因为如果encdoer与Decoder是简单的傅里叶变换,在理论意义上可以精准还原回来,但是如果encoder与Decoder是一个网络,很可能引入误差, 所以他先悬链两端,使得两端变换引入的误差尽可能的小,再继续进行后续Separator的训练Dynamic mixing for data augmentation 动态混合
它是一种典型的数据增广的一种方式,尽可能地多利用训练数据Mixup-breakdown training (MBT)
腾讯Conditional chain model
适用于说话人个数未知的场景
思想是将说话人语音一个一个地输出,并且再后续输出过程中,会利用已经分离地说话人语音,是一种串型分离地思路。停止条件需要设计,在一定程度上可以解决输出维度问题One-and-rest PIT, OR-PIT
与上面类似也是串型接收
一般这种串型分离地方案,在少于五个说话人之人的数据表现性能还可以。
usage of spkr-embedding(针对说话人提取) 抽取网络设计
- 无embedding:
Conv-TasNet, DPRNN-TasNet, … - 固定的embedding:
Fbank, x-vector, d-vector, …
例如: Voice filter - 网络学习出的embedding:
通常会有一个显式的 speaker encoder 与抽取器联合训练;
通常会引入CE loss;
speaker encoder 与 speech encoder 的配合;
例如: SpEx, SpEx+, Wavesplit, Atss-Net
3、多通道语音分离技术
大致分为三种方法:
3.1 Separation-wise methods
利用多通道带来的空间信息帮助一个分离网络更好的工作;
使用固定类空间特征:IPD、ILD、…;
使用网络学习的空间特征
3.2 Beamforming-wise methods
将分离网络看作一个前端模块,帮助Beamformer更好的工作;
Beam-TasNet: 为频域波束形成(如MVDR)提供更可靠的统计量估计
FaSNet: 直接估计波束形成器中每个滤波器的系数
3.3 Pipeline / end-to-end solution
unmixing, fix-beamformer, extraction (UFE) [34]
end-to-end UFE (E2E-UFE)




