类MOOC系统开发2-媒资管理模块开发
媒资管理大体功能介绍
媒资查询:教学机构查询自己所拥有的媒资信息。
文件上传:包括上传图片、上传文档、上传视频。
视频处理:视频上传成功,系统自动对视频进行编码处理。
审核: 自动审核(自动校验鉴黄接口)

为什么要媒资管理
统一进行文件管理
将文件(图片、视频、文档)本身放进分布式文件系统当中。
叫文件信息存入数据库当中
其中的文件上传下载等功能接口需要给其他模块调用。
如:冗余文件上传校验 (避免重复上传)
搭建网关微服务(gateway)
为什么要网关?
1、降低前端与后端对接成本,网关作为前后端连接的中间层,不需要前端写死调用的微服务资源地址(到时候上线微服务地址可能会变还要改,麻烦)
2、具体作用
路由转发(针对不同微服务功能)、负载均衡(针对于同一微服务的不同实例)
还能实现认证授权 限流

项目采用Spring Cloud Gateway作为网关,网关在请求路由时需要知道每个微服务实例的地址,项目使用Nacos作用服务注册/发现中心和配置中心,整体的架构图如下

网关的工作流程
1、微服务启动,将自己注册到Nacos,Nacos记录了各微服务实例的地址。
2、网关从Nacos读取服务列表,包括服务名称、服务地址等。
3、请求到达网关,网关将请求路由到具体的微服务。
所以为了能让网关顺利获取各个微服务实例地址,需要先搭建一个Nacos 注册/发现 配置 中心 。
要使用网关首先搭建Nacos,Nacos有两个作用:
1、服务发现中心。
微服务将自身注册至Nacos,网关从Nacos获取微服务列表。
2、配置中心。
微服务众多,它们的配置信息也非常复杂,为了提供系统的可维护性,微服务的配置信息统一在Nacos配置。
Spring Cloud
Spring Cloud :一套规范
Spring Cloud alibaba: 根据这套提出了多种实现案例
- nacos 服务注册中心,配置中心
- 远程调用(RPC) feign
- Sentinel 一种限流、熔断中间件
根据上节讲解的网关的架构图,要使用网关首先搭建Nacos。
首先搭建Nacos服务发现中心。
搭建Nacos
在此之前我们先下载安装并启动
拉取镜像
docker pull nacos/nacos-server:1.4.1创建并运行一个容器
docker run --name nacos -e MODE=standalone -p 8849:8848 -d nacos/nacos-server:1.4.1访问
虚拟机ip:8848/nacos登录,默认的账号密码均为nacos

啊折腾了一下午,终于搞出来了,不知道为啥之前总是报错或者启动不起来。。。。。
索性试了好好几个版本的镜像

上报(注册)服务
搭建Nacos服务发现中心之前,需要搞清楚两个概念
- namespace:用于区分环境,例如:开发环境dev、测试环境test、生产环境prod
- group:用于区分项目,例如xuecheng-plus、reggie项目
点击左侧菜单“命名空间”进入命名空间管理界面,新建命名空间


如何把服务上报到 nacos呢?
首先要把要上报的服务导入nacos依赖
- 在parent 工程添加依赖管理(第一节已经添加)
<properties>
<spring-cloud-alibaba.version>2.2.6.RELEASE</spring-cloud-alibaba.version>
</properties>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>- 如果要上报服务信息(让nacos发现该服务实例) 需要在要启动实例的 工程(system , content, gateway还没建) 添加nacos依赖
- 第二点,content 有三个服务 分别是 api service model 该上报哪一个呢? 答案是上报api 因为 是api 工程启动的整个服务,http服务,所以在content api pom文件中添加依赖
- 如果有一天 service 也需要往上报服务,那么到时候将 service 也添加整个依赖即可。
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-nacos-discovery</artifactId>
</dependency>在系统管理的接口工程的配置文件中配置如下信息:配置nacos地址
上报四要素
总体来说用四项(服务名、上报地址、命名空间、项目组)就可以把自己的服务上报上去
#微服务配置
spring:
application:
name: system-api
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project同理上报system服务
PS: 我们学习的 spring cloud 里面的feign 其底层是基于HTTP/TCP协议的,而 dubbo 技术底层基于RPC/TCP,所以远程调用微服务接口调用的比较频繁,建议用dubbo,如果 servcie 提供了dubbo服务,那么service也要上报(添加依赖,配置nacos)
重启服务。
报错,发现是
发现又报错,无法上报服务。。。。。
我认为还是版本问题,

依赖版本导致无法读取nacos配置
查证:
所有的依赖都是从镜像网站http://maven.aliyun.com/nexus/content/groups/public 下载的,我就往这个网站看了看
搜了以下这个仓库,果然没有 2.2.6 这个版本。。。

emmmm,真够傻逼的
就改成了2.2.1这个版本

可以解析了,应该没问题了,打开nacos
服务也顺利上报了。。。
好累

配置服务
nacos的另一个功能就是配置微服务,以后 微服务里面的 配置信息就可以不用写或者写的很少了。
更重要的是,这些配置信息可以根据环境(开发,生产,测试)切换,也可以设置通用配置,这就很nice了
PS:记得在被配置的项目pom文件上添加 config 依赖(作用 从 nacos 定时拉取配置到本地)
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>配置分类
微服务特有的配置
服务名spring.application.name 、端口 、servlet路径(访问路径)
微服务通用的配置
例如redis的配置,很多项目用的同一套redis服务,所以配置也一样
微服务扩展配置
如 api 可以 引用 servcie 数据库相关配置
(被)配置三要素
Nacos 如何去定位一个具体的配置?
nacos制定了这样一套规则,强制性的!!!
分三个要素
- namespace : 环境
- group:项目
data id: (在nocas中具体的) 配置文件名,配置文件名具体也分三个要素 如 例如
content-service-dev.yml- 应用名:
content-service,特指在application.yml中配置的应用名 - 环境名:
dev由spring.profile.active指定 ,(一般和 namespace对应) - 文件类型:
file-extension: .yaml.yml注意 yml 与 yaml等价,但是一定要本地一定要和 nocas真正的文件后缀对应,否则会报错。。。
- 应用名:
所以,如果我们要配置content-service工程的配置文件
- 在开发环境中配置content-service-dev.yml
- 在生产环境中配置content-service-prod.yml
- 在测试环境中配置content-service-test.yml
下面对 content-api 进行配置上传
原本本地的配置放在 content-api resources 目录下的bootstrap里面,具体配置是这样的。
server:
servlet:
context-path: /content
port: 63040
#微服务配置
spring:
application:
name: content-api
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.101.65:3306/xc_content?serverTimezone=UTC&userUnicode=true&useSSL=false
username: root
password: root
#微服务配置
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project
profiles:
active: dev
# 日志文件配置路径
logging:
config: classpath:log4j2-dev.xml
# swagger 文档配置
swagger:
title: "学成在线内容管理"
description: "系统管理接口"
base-package: com.xuecheng.system
enabled: true
version: 1.0.0
现在,我们之后将用nacos配置中心的配置代替原来这个配置,这个文件里面只会放一些基础的配置。
现在我们打开nacos 配置列表,新建配置
按照上面的约定,我们的配置文件的名称应该叫content-api-dev.yml(也即 data id)
本地配置
此外,想一想,配置文件那些配置可以交到nacos管理呢,又有哪些不能交由 nacos管理必须留在本地呢?
其实很明晰的:
除了上报服务所需要的那四个关键点(服务名、上报地址、命名空间(开发环境)、项目组)其他的都可以上报
除此之外,上面这四项只是为了上报服务,然后然后被发现, 如果想要 被配置 还需要 本地配置一些额外的信息
总的来说,本地最少最少应该有这些东西
#微服务配置
spring:
application:
name: content-api
#微服务配置
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project
#服务如果想要 “被配置”,本地需要配置如下信息(前面是上报四要素,下面是配置三要素)
#也即配置三要素
config:
namespace: dev
group: xuecheng-plus-project
# 必须写 yml 要与nacos 后缀一致,否则报错。。。 可能和依赖版本有关。。。
file-extension: yml
refresh-enabled: true
# 环境名,也是nacos dataid中拼接的那个东东
profiles:
active: dev
nacos配置
其他所有的内容都可以放到nacos配置(文件名应该为 content-api-dev.yml )上面了,来看看都有什么:
server:
servlet:
context-path: /content
port: 63040
#微服务配置
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.101.65:3306/xc_content?serverTimezone=UTC&userUnicode=true&useSSL=false
username: root
password: root
# 日志文件配置路径
logging:
config: classpath:log4j2-dev.xml
# swagger 文档配置
swagger:
title: "学成在线内容管理"
description: "系统管理接口"
base-package: com.xuecheng.system
enabled: true
version: 1.0.0启动服务,正常启动

可以发现微服务定时向 nacos 发送心跳信息。
配置改进
在api工程中其实不需要 数据库连接配置,应为 与数据库直接交互的应该是 持久层 service 与持久层交互,所以,只应该在 service配置一下,如果api用到了数据库,只用“引用”service层的配置即可。
所以分两步
1、把service层的配置(数据库等)放到nacos中
2、接口层 api 引用service 层的数据库配置。
配置service
注意导入依赖
问: service 需要上报服务吗? 不需要,所以其实可以只导入config即可,但是上报可无伤大雅(其实不会被上报上去,因为没有启动类)
service层只需要配置一个数据源即可

service本地配置(就直接在test 目录的 配置。)
spring:
application:
name: content-service
#微服务配置
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project
#服务如果想要 “被配置”,本地需要配置如下信息(前面是上报四要素,下面是配置三要素)
#也即配置三要素
config:
namespace: dev
group: xuecheng-plus-project
file-extension: yml
refresh-enabled: true
# 环境名,也是nacos dataid中拼接的那个东东
profiles:
active: dev
测试原来的文件那些 test 函数,发现可以正常启动,所以,读取到了nacos的配置。
api 扩展配置
#微服务配置
spring:
application:
name: content-api
#微服务配置
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project
#服务如果想要 “被配置”,本地需要配置如下信息(前面是上报四要素,下面是配置三要素)
#也即配置三要素
config:
namespace: dev
group: xuecheng-plus-project
# 必须写 yml 要与nacos 后缀一致,否则报错。。。 可能和依赖版本有关。。。
file-extension: yml
refresh-enabled: true
extension-configs:
+ - data-id: content-service-${spring.profiles.active}.yaml
+ group: xuecheng-plus-project
+ refresh: true
# 环境名,也是nacos dataid中拼接的那个东东
profiles:
active: dev然后就可以把 原来 nacos content-api-dev.yml 里面的数据库配置部分删去了

重启服务
功能正常!!!
公用配置
所有的微服务都需要日志,所有的结构都需要swagger文档,这个也可以提取出来
单独在xuecheng-plus-common分组下创建公用配置,进入nacos的开发环境,添加swagger-dev.yaml公用配置

同理 添加logging-dev.yaml 用用配置
然后把 nacos 里面 api对应的配置注释掉
那么最终 本地api 配置可以写成
#微服务配置
spring:
application:
name: content-api
#微服务配置
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project
#服务如果想要 “被配置”,本地需要配置如下信息(前面是上报四要素,下面是配置三要素)
#也即配置三要素
config:
namespace: dev
group: xuecheng-plus-project
# 必须写 yml 要与nacos 后缀一致,否则报错。。。 可能和依赖版本有关。。。
file-extension: yml
refresh-enabled: true
# 扩展配置,其实就是读取了数据库
extension-configs:
- data-id: content-service-${spring.profiles.active}.yaml
group: xuecheng-plus-project
refresh: true
# 通用配置 所有的微服务都需要日志,所有的结构都需要swagger文档,这个也可以提取出来
shared-configs:
- data-id: swagger-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
- data-id: logging-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
# 环境名,也是nacos dataid中拼接的那个东东
profiles:
active: dev这样看起来有点变复杂了,但其实通用性更强,以后不需要再这里该配置,在nacos 改改就行了。
配置优先级问题
读取顺序
SpringBoot读取配置文件 的顺序如下

首先读取bootstrap.yml,获取nacos 地址,读取 nacos 配置
将所有本地配置 与 nacos 配置文件合并(这里合并的优先级?称为配置优先级)
配置优先级顺序
项目应用名配置文件(content-api-dev.yaml) > 扩展配置文件(content-service-dev.html) > 共享配置文件(swagger-dev.yaml) > 本地配置文件(bootstrap.yml>application.yml)
总结 外部配置(前三个都在nacos)大于内部配置
举例:启动一个服务多个实例
如果远程已经配置了端口
在本地如果你想在开启一个实例 ,仅仅在本地 yml 文件上增加端口信息(想覆盖远端的端口信息)是不能尘垢构建实例的,报端口占用错误。

点击复制

解决方案:nocas 设置本地优先
步骤1、

步骤2 在nacos 配置本地优先
#配置本地优先
spring:
cloud:
config:
override-none: true
启动成功

用途:
还可以 在 VM 参数中输入
-Dserver.port=63041 spring.profiles.active=dev
这样就可以随时切换环境了。
搭建网关
本项目使用Spring Cloud Gateway作为网关,下边创建网关工程。

导入网关依赖
指定父工程添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!--指定父工程为xuecheng-plus-parent-->
<parent>
<groupId>com.xuecheng</groupId>
<artifactId>xuecheng-plus-parent</artifactId>
<version>0.0.1-SNAPSHOT</version>
<relativePath>../xuecheng-plus-parent</relativePath>
</parent>
<artifactId>xuecheng-plus-gateway</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>xuecheng-plus-gateway</name>
<description>xuecheng-plus-gateway</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--服务发现中心-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!-- 排除 Spring Boot 依赖的日志包冲突 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Spring Boot 集成 log4j2 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
</dependencies>
</project>本地配置
YAML
#微服务配置
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 192.168.101.65:8848
discovery:
namespace: dev
group: xuecheng-plus-project
config:
namespace: dev
group: xuecheng-plus-project
file-extension: yaml
refresh-enabled: true
shared-configs:
- data-id: logging-${spring.profiles.active}.yaml
group: xuecheng-plus-common
refresh: true
profiles:
active: dev
远端配置(路由策略)
网关具有路由转发的功能,其路由策略可直接在routes属性里面配置
springboot
PS:
在gateway中配置uri配置有三种方式,包括
第一种:ws(websocket)方式: uri: ws://localhost:9000
第二种:http方式: uri: http://localhost:8130/
第三种:lb(注册中心中服务名字)方式: uri: lb://brilliance-consumer
server:
port: 63010 # 网关端口
spring:
cloud:
gateway:
# filter:
# strip-prefix:
# enabled: true
routes: # 网关路由配置
- id: content-api # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081 # 路由的目标地址 http就是固定地址
uri: lb://content-api # 路由的目标地址 lb就是负载均衡,后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/content/** # 这个是按照路径匹配,只要以/content/开头就符合要求
# filters:
# - StripPrefix=1
- id: system-api
# uri: http://127.0.0.1:8081
uri: lb://system-api
predicates:
- Path=/system/**
# filters:
# - StripPrefix=1
- id: media-api
# uri: http://127.0.0.1:8081
uri: lb://media-api
predicates:
- Path=/media/**
# filters:
# - StripPrefix=1
http client 设置 gateway 地址
{
"dev": {
"host": "localhost:53010",
"content_host": "localhost:53040",
"system_host": "localhost:53110",
"media_host": "localhost:53050",
"cache_host": "localhost:53035",
+ "gateway_host": "localhost:53010"
}
}启动gateway服务
查询测试是否正常

以后可以外部调用微服务可以走统一的端口啦!
那么网关工程搭建完成即可将前端工程中的接口地址改为网关的地址

搭建媒资工程
至此网关、Nacos已经搭建完成,下边将媒资工程导入项目
从课程资料中获取媒资工程 xuecheng-plus-media,拷贝到项目工程根目录。
右键pom.xml转为maven工程。
下边做如下配置:
1、创建媒资数据库xc_media,并导入资料目录中的xcplus_media.sql
2、修改nacos上的media-service-dev.yaml配置文件中的数据库链接信息
重启media-api工程只要能正常启动成功即可,稍后根据需求写接口。
分布式文件系统
什么是分布式文件系统
简单来说就是大量计算机组成的一个容量超大的文件存储管理系统,外界看起来是一个整体。

优势:
1、性能 (多个计算机同时处理)
2、安全(多数具有备份能力)
3、访问快捷 (放在不同地域,就近访问提高速度)
市面上有哪些分布式文件系统的产品呢?
1、NFS
NFS是基于UDP/IP协议的应用,其实现主要是采用远程过程调用RPC机制,RPC提供了一组与机器、操作系统以及低层传送协议无关的存取远程文件的操作。RPC采用了XDR的支持。XDR是一种与机器无关的数据描述编码的协议,他以独立与任意机器体系结构的格式对网上传送的数据进行编码和解码,支持在异构系统之间数据的传送。
特点
- 在客户端上映射NFS服务器的驱动器
- 客户端通过万国访问NFS服务器的硬盘完全透明
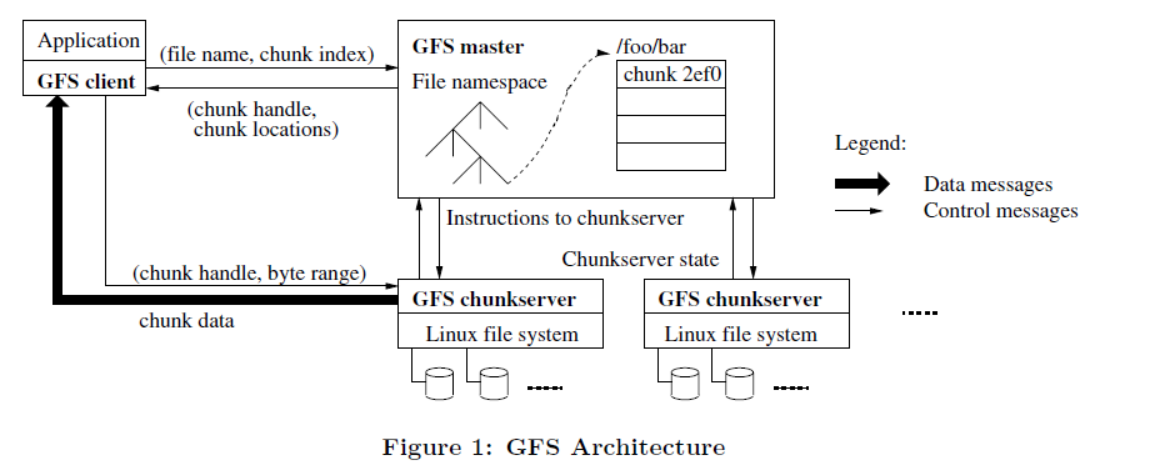
2、GFS
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务。
- GFS采用主从结构,一个GFS集群由一个master和大量的chunkserver组成
- master存储了数据文件的元数据,一个文件被分成了若干块存储在多个chunkserver中
- 用户从master中获取数据元信息,向chunkserver存储数据
3、HDFS
Hadoop 框架下的分布式文件系统
1)HDFS采用主从结构,一个HDFS集群由一个名称结点(nameNode)和若干数据结点(DataNode)组成。
2) 名称结点存储数据的元信息,一个完整的数据文件分成若干块存储在数据结点。
3)客户端从名称结点获取数据的元信息及数据分块的信息,得到信息客户端即可从数据块来存取数据。
4、云对象
云计算厂家
- 阿里云对象存储服务(Object Storage Service,简称 OSS)(本博客使用的就是
- 百度对象存储BOS提供稳定、安全、高效、高可扩展的云存储服务。
MinIO
- 本项目采用MinIO构建分布式文件系统,MinIO是一个非常轻量的服务,可以很简单的和其他应用结合使用。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等
- 它的一大特点就是轻量,使用简单、功能强大,支持各种平台,单个文件最大5TB,兼容提供了Java、Python、GO等多版本SDK支持
- 官网:https://min.io/,
- 中文:https://www.minio.org.cn/, http://docs.minio.org.cn/docs/
它将分布在不同服务器上的多块硬盘组成一个对象存储服务。由于硬盘分布在不同的节点上,分布式MinIO避免了单点故障

- MinIO使用纠删码技术来保护数据,它是一种恢复丢失和损坏数据的数学算法,它将数据分块,冗余地分散存储在各个节点的磁盘上,所有可用的磁盘组成一个集合,上图由8块硬盘组成一个集合,当上传一个文件时,会通过纠删码算法计算对文件进行分块存储,除了将文件本身分成4个数据块,还会生成4个校验块,数据块和校验开会分散的存储在这8块硬盘上
使用纠删码的好处是即便丢失一半数量(N/2)的硬盘,仍可以恢复数据。例如上面集合中有4个以内的硬盘损害,仍可保证数据恢复,不影响上传和下载;但如果多余一半的硬盘损坏,则无法恢复
安装 MinIO
windows
- MinIO下载地址:https://dl.min.io/server/minio/release/
安装完毕后,CMD进入minio.exe所在目录,执行下面的命令,会在D盘创建4个目录,模拟4个硬盘
注意改成自己的目录
minio.exe server E:\software\MinIO\minio_data\data1 E:\software\MinIO\minio_data\data2 E:\software\MinIO\minio_data\data3 E:\software\MinIO\minio_data\data4
- 默认账号密码均为
minioadmin,访问localhost:9000进行登录
进入后
之后创建两个buckets(文件目录)
mediafiles:普通文件video:视频文件
将访问权限给位public

linux
docker pull minio/minio
//一个用来存放配置,一个用来存储上传文件的目录
//启动前需要先创建Minio外部挂载的配置文件( /home/minio/config),和存储上传文件的目录( /home/minio/data)
mkdir -p /home/minio/config
mkdir -p /home/minio/data
//创建容器并运行
docker run -p 9000:9000 -p 9090:9090 \
--net=host \
--name minio \
-d --restart=always \
-e "MINIO_ACCESS_KEY=minioadmin" \
-e "MINIO_SECRET_KEY=minioadmin" \
-v /home/minio/data:/data \
-v /home/minio/config:/root/.minio \
minio/minio server \
/data --console-address ":9090" -address ":9000"MinIO java SDK配置
MinIO提供多个语言版本SDK的支持,下边找到java版本的文档:
地址:https://docs.min.io/docs/java-client-quickstart-guide.html
最低需求Java 1.8或更高版本:
在media-service工程中添加依赖
<dependency>
<groupId>io.minio</groupId>
<artifactId>minio</artifactId>
<version>8.4.3</version>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.8.1</version>
</dependency>
- 从官方文档中看到,需要三个参数才能连接到minio服务
| Parameters | Description |
|---|---|
| Endpoint | URL to S3 service. |
| Access Key | Access key (aka user ID) of an account in the S3 service. |
| Secret Key | Secret key (aka password) of an account in the S3 service. |
分析官方给出的代码如下
public class FileUploader {
public static void main(String[] args)
throws IOException, NoSuchAlgorithmException, InvalidKeyException {
try {
// 1、创建客户端
// Create a minioClient with the MinIO server playground, its access key and secret key.
// 创建MinIO客户端,连接参数就是上述表格中的三个参数,127.0.0.1:9000、minioadmin、minioadmin
MinioClient minioClient =
MinioClient.builder()
.endpoint("https://play.min.io")
.credentials("Q3AM3UQ867SPQQA43P2F", "zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG")
.build();
// 创建桶
// Make 'asiatrip' bucket if not exist.
// 由于backet我们已经手动创建了,所以这段代码可以删掉
boolean found =
minioClient.bucketExists(BucketExistsArgs.builder().bucket("asiatrip").build());
if (!found) {
// Make a new bucket called 'asiatrip'.
minioClient.makeBucket(MakeBucketArgs.builder().bucket("asiatrip").build());
} else {
System.out.println("Bucket 'asiatrip' already exists.");
}
// 上传文件到桶
// Upload '/home/user/Photos/asiaphotos.zip' as object name 'asiaphotos-2015.zip' to bucket
// 'asiatrip'.
// 将 '/home/user/Photos/asiaphotos.zip' 文件命名为 'asiaphotos-2015.zip'
// 并上传到 'asiatrip' 里(示例代码创建的bucket)
minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket("asiatrip")
.object("asiaphotos-2015.zip")
.filename("/home/user/Photos/asiaphotos.zip")
.build());
// 这段输出也没有用,可以直接删掉
System.out.println(
"'/home/user/Photos/asiaphotos.zip' is successfully uploaded as "
+ "object 'asiaphotos-2015.zip' to bucket 'asiatrip'.");
} catch (MinioException e) {
System.out.println("Error occurred: " + e);
System.out.println("HTTP trace: " + e.httpTrace());
}
}
}上传测试
package com.xuecheng.media;
import io.minio.MinioClient;
import io.minio.UploadObjectArgs;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest
public class MinIOTest {
// 创建MinioClient对象
static MinioClient minioClient =
MinioClient.builder()
.endpoint("http://192.168.101.65:9000")
.credentials("minioadmin", "minioadmin")
.build();
/**
* 上传测试方法
*/
@Test
public void uploadTest() {
try {
minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket("testbucket")
.object("test/111.png") // 同一个桶内对象名不能重复
.filename("E:\\test\\picture\\111.png")
.build()
);
System.out.println("上传成功");
} catch (Exception e) {
System.out.println("上传失败");
}
}
}

删除测试
@Test
public void delete(){
try {
minioClient.removeObject(
RemoveObjectArgs.builder().bucket("testbucket").object("test/111.png").build());
System.out.println("删除成功");
} catch (Exception e) {
e.printStackTrace();
System.out.println("删除失败");
}
}
查询测试
通过查询文件查看文件是否存在minio中。
下载校验
校验文件的完整性,对文件计算出md5值,比较原始文件的md5和目标文件的md5,一致则说明完整
@Test
public void getFileTest() {
try {
InputStream inputStream = minioClient.getObject(GetObjectArgs.builder()
.bucket("testbucket")
.object("test/111.png")
.build());
FileOutputStream fileOutputStream = new FileOutputStream("E:\\test\\picture\\tmp1.png");
byte[] buffer = new byte[1024];
int len;
while ((len = inputStream.read(buffer)) != -1) {
fileOutputStream.write(buffer,0,len);
}
inputStream.close();
fileOutputStream.close();
System.out.println("下载成功");
} catch (Exception e) {
System.out.println("下载失败");
}
}用IOUtils简化代码
@Test
public void getFileTest1() {
try {
InputStream inputStream = minioClient.getObject(GetObjectArgs.builder()
.bucket("testbucket")
.object("test/111.png")
.build());
FileOutputStream fileOutputStream = new FileOutputStream("E:\\test\\picture\\temp1.png");
IOUtils.copy(inputStream,fileOutputStream);
//校验文件的完整性对文件的内容进行md5
String source_md5 = DigestUtils.md5Hex(inputStream);
String local_md5 = DigestUtils.md5Hex(fileOutputStream);
if(source_md5.equals(local_md5)){
System.out.println("下载成功");
}
} catch (Exception e) {
System.out.println("下载失败");
}
}文件扩展名获取
设置contentType可以通过com.j256.simplemagic.ContentType枚举类查看常用的mimeType(媒体类型)
//根据扩展名取出mimeType
ContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(".mp4");
String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;//通用mimeType,字节流MD5校验
String local_md5 = DigestUtils.md5Hex(“输入流”);
@Test
public void getFileTest1() {
try {
InputStream inputStream = minioClient.getObject(GetObjectArgs.builder()
.bucket("testbucket")
.object("test/111.png")
.build());
FileOutputStream fileOutputStream = new FileOutputStream("E:\\test\\picture\\temp1.png");
IOUtils.copy(inputStream,fileOutputStream);
//校验文件的完整性对文件的内容进行md5
FileInputStream fileInputStream = new FileInputStream("E:\\test\\picture\\temp1.png");
String minIO_md5 = DigestUtils.md5Hex(inputStream);
String down_md5 = DigestUtils.md5Hex(fileInputStream);
if(minIO_md5.equals(down_md5)){
System.out.println("minio与下载文件校验一致");
}else{
System.out.println("minio与下载文件校验不一致?"); //为什么?
}
FileInputStream originInputStream = new FileInputStream("E:\\test\\picture\\111.png");
String origin_local_md5 = DigestUtils.md5Hex(originInputStream);
if(origin_local_md5.equals(down_md5)){
System.out.println("本地与下载文件校验一致");
}else{
System.out.println("本地与下载文件校验不一致");
}
} catch (Exception e) {
System.out.println("下载失败");
}
}输出如下
minio与下载文件校验不一致?
本地与下载文件校验一致为什么?
远程流不稳定,所以完整性校验只能 下载完整后校验。。。。。。
功能1:上传文件
需求分析
我们在新增课程的时候 需要有一个上传图片的功能
这个步骤其实用了两个微服务两个步骤
- 1、图片上传: 将图片上传到 MinIO 并将图片信息(包括地址信息)存到媒资管理数据库中
- 2、更新课程信息表: 课程信息中保存课程图片路径
注意不能直接将图片地址复制到课程信息表(不好修改)
为了验证是否重复上传,一般使用 md5值作为文件信息的 主键。

环境准备
nacos配置 media-service-dev
spring:
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.101.65:3306/xc_media?serverTimezone=UTC&userUnicode=true&useSSL=false&
username: root
password: root
cloud:
config:
override-none: true
minio:
endpoint: http://192.168.101.65:9000
accessKey: minioadmin
secretKey: minioadmin
bucket:
files: mediafiles
videofiles: video
xxl:
job:
admin:
addresses: http://192.168.101.65:8088/xxl-job-admin
executor:
appname: media-process-service
address:
ip:
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token
videoprocess:
ffmpegpath: E:/software/FFmpeg/ffmpeg.exe
在media-service工程编写minio的配置类:
package com.xuecheng.media.config;
@Configuration
public class MinioConfig {
@Value("${minio.endpoint}")
private String endpoint;
@Value("${minio.accessKey}")
private String accessKey;
@Value("${minio.secretKey}")
private String secretKey;
@Bean
public MinioClient minioClient() {
MinioClient minioClient =
MinioClient.builder()
.endpoint(endpoint)
.credentials(accessKey, secretKey)
.build();
return minioClient;
}
}
接口定义
根据需求分析,下边进行接口定义,此接口定义为一个通用的上传文件接口,可以上传图片或其它文件。
首先分析接口:
请求地址:/media/upload/coursefile
请求头内容:
Content-Type: multipart/form-data;boundary=…..
FormData: filedata=??,
folder=?,
objectName=?
form-data; name="filedata"; filename="具体的文件名称"
接收DTO(上传应该就是把图片上传到系统并返回信息的过程)
定义上传返回信息模型类,虽然响应结果与MediaFiles表中的字段完全一致,但最好不要直接用MediaFiles类。因为该类属于PO类,如果后期我们要对响应结果进行修改,那么模型类也需要进行修改,但是MediaFiles是PO类,我们不能动。所以可以直接用一个类继承MediaFiles,里面什么属性都不用加
@Data
public class UploadFileResultDto extends MediaFiles {
}
上传图片
/**
filedata 上传的文件
folder
*/
@ApiOperation("上传文件")
@RequestMapping(value = "/upload/coursefile",consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public UploadFileResultDto upload(@RequestPart("filedata") MultipartFile filedata,
@RequestParam(value = "folder", required = false) String folder,
@RequestParam(value = "objectName", required = false) String objectName) {
return null;
}先用 httpclinet测试一下
### 上传文件
POST {{media_host}}/media/upload/coursefile
Content-Type: multipart/form-data; boundary=WebAppBoundary
--WebAppBoundary
Content-Disposition: form-data; name="filedata"; filename="1.jpg"
Content-Type: application/octet-stream
< e:/test/picture/222.png
接口开发
定义请求通用参数类(适用于更多的文件类型):
@Data
@ToString
public class UploadFileParamsDto {
/**
* 文件名称
*/
private String filename;
/**
* 文件content-type
*/
private String contentType;
/**
* 文件类型(文档,图片,视频)
*/
private String fileType;
/**
* 文件大小
*/
private Long fileSize;
/**
* 标签
*/
private String tags;
/**
* 上传人
*/
private String username;
/**
* 备注
*/
private String remark;
}定义service方法,MultipartFile是SpringMVC提供简化上传操作的工具类,不使用框架之前,都是使用原生的HttpServletRequest来接收上传的数据,文件是以二进制流传递到后端的。为了使接口更通用,我们可以用字节数组代替MultpartFile类型
/**
* 上传文件
* @param companyId 机构id
* @param uploadFileParamsDto 上传文件信息
* @param localFilePath 文件磁盘路径
* @return 文件信息
*/
public UploadFileResultDto uploadFile(Long companyId, UploadFileParamsDto uploadFileParamsDto, String localFilePath);- 实现方法如下,主要分为两部分
- 将文件上传到minio
- 将文件信息写入media_file表中
service实现
@Autowired
MinioClient minioClient;
@Autowired
MediaFilesMapper mediaFilesMapper;
//普通文件桶
@Value("${minio.bucket.files}")
private String bucket_Files;
/**
* @description 将文件写入minIO
* @param localFilePath 文件地址
* @param bucket 桶
* @param objectName 对象名称
* @return void
* @author Mr.M
* @date 2022/10/12 21:22
*/
@Transactional
@Override
public UploadFileResultDto uploadFile(Long companyId, UploadFileParamsDto uploadFileParamsDto, String localFilePath) {
File file = new File(localFilePath);
if (!file.exists()) {
XueChengPlusException.cast("文件不存在");
}
//文件名称
String filename = uploadFileParamsDto.getFilename();
//文件扩展名
String extension = filename.substring(filename.lastIndexOf("."));
//文件mimeType
String mimeType = getMimeType(extension);
//文件的md5值
String fileMd5 = getFileMd5(file);
//文件的默认目录
String defaultFolderPath = getDefaultFolderPath();
//存储到minio中的对象名(带目录)
String objectName = defaultFolderPath + fileMd5 + exension;
//将文件上传到minio
boolean b = addMediaFilesToMinIO(localFilePath, mimeType, bucket_files, objectName);
//文件大小
uploadFileParamsDto.setFileSize(file.length());
//将文件信息存储到数据库
MediaFiles mediaFiles = addMediaFilesToDb(companyId, fileMd5, uploadFileParamsDto, bucket_files, objectName);
//准备返回数据
UploadFileResultDto uploadFileResultDto = new UploadFileResultDto();
BeanUtils.copyProperties(mediaFiles, uploadFileResultDto);
return uploadFileResultDto;
}
public boolean addMediaFilesToMinIO(String localFilePath,String mimeType,String bucket, String objectName) {
try {
UploadObjectArgs testbucket = UploadObjectArgs.builder()
.bucket(bucket)
.object(objectName)
.filename(localFilePath)
.contentType(mimeType)
.build();
minioClient.uploadObject(testbucket);
log.debug("上传文件到minio成功,bucket:{},objectName:{}",bucket,objectName);
System.out.println("上传成功");
return true;
} catch (Exception e) {
e.printStackTrace();
log.error("上传文件到minio出错,bucket:{},objectName:{},错误原因:{}",bucket,objectName,e.getMessage(),e);
XueChengPlusException.cast("上传文件到文件系统失败");
}
return false;
}
/**
* @description 将文件信息添加到文件表
* @param companyId 机构id
* @param fileMd5 文件md5值
* @param uploadFileParamsDto 上传文件的信息
* @param bucket 桶
* @param objectName 对象名称
* @return com.xuecheng.media.model.po.MediaFiles
* @author Mr.M
* @date 2022/10/12 21:22
*/
@Transactional
public MediaFiles addMediaFilesToDb(Long companyId,String fileMd5,UploadFileParamsDto uploadFileParamsDto,String bucket,String objectName){
//从数据库查询文件
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
//拷贝基本信息
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMd5);
mediaFiles.setFileId(fileMd5);
mediaFiles.setCompanyId(companyId);
mediaFiles.setUrl("/" + bucket + "/" + objectName);
mediaFiles.setBucket(bucket);
mediaFiles.setFilePath(objectName);
mediaFiles.setCreateDate(LocalDateTime.now());
mediaFiles.setAuditStatus("002003");
mediaFiles.setStatus("1");
//保存文件信息到文件表
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert < 0) {
log.error("保存文件信息到数据库失败,{}",mediaFiles.toString());
XueChengPlusException.cast("保存文件信息失败");
}
log.debug("保存文件信息到数据库成功,{}",mediaFiles.toString());
}
return mediaFiles;
}
//获取文件默认存储目录路径 年/月/日/
private String getDefaultFolderPath() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String folder = sdf.format(new Date()).replace("-", "/")+"/";
return folder;
}
//获取文件的md5
private String getFileMd5(File file) {
try (FileInputStream fileInputStream = new FileInputStream(file)) {
String fileMd5 = DigestUtils.md5Hex(fileInputStream);
return fileMd5;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
private String getMimeType(String extension){
if(extension==null)
extension = "";
//根据扩展名取出mimeType
ContentInfo extensionMatch = ContentInfoUtil.findExtensionMatch(extension);
//通用mimeType,字节流
String mimeType = MediaType.APPLICATION_OCTET_STREAM_VALUE;
if(extensionMatch!=null){
mimeType = extensionMatch.getMimeType();
}
return mimeType;
}
完善接口
@ApiOperation("上传文件")
@RequestMapping(value = "/upload/coursefile",consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
@ResponseBody
public UploadFileResultDto upload(@RequestPart("filedata") MultipartFile filedata,
@RequestParam(value = "folder",required=false) String folder,
@RequestParam(value = "objectName",required=false) String objectName) throws IOException {
Long companyId = 1232141425L;
UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();
//文件大小
uploadFileParamsDto.setFileSize(filedata.getSize());
//图片
uploadFileParamsDto.setFileType("001001");
//文件名称
uploadFileParamsDto.setFilename(filedata.getOriginalFilename());//文件名称
//文件大小
long fileSize = filedata.getSize();
uploadFileParamsDto.setFileSize(fileSize);
//创建临时文件(在服务器中,toamcat的一个指定地址上)
File tempFile = File.createTempFile("minio", "temp");
//上传的文件拷贝到临时文件
filedata.transferTo(tempFile);
//文件路径
String absolutePath = tempFile.getAbsolutePath();
//上传文件
UploadFileResultDto uploadFileResultDto = mediaFileService.uploadFile(companyId, uploadFileParamsDto, absolutePath);
return uploadFileResultDto;
}
测试接口
关于测试中的
—WebAppBoundary 含义
以及为什么有两个 Content Type 其实 ,我们宏观上接受的 content type 是第一个
第二个content type 其实是表单自带的 content type

前后端联调:

终于成功了,之前网关除了 conten总是不生效。。。问题在哪里,也没查出来,最后也没改啥,把所有服务重启了一遍才好。。。。。
我真的崩溃了。。
Service事务优化(事务注解失效)
上边的service方法优化后并测试通过,现在思考关于uploadFile方法的是否应该开启事务。
目前是在uploadFile方法上添加@Transactional,当调用uploadFile方法前会开启数据库事务,如果上传文件过程时间较长那么数据库的事务持续时间就会变长,这样数据库链接释放就慢,最终导致数据库链接不够用。
我们只将addMediaFilesToDb方法添加事务控制即可,uploadFile方法上的@Transactional注解去掉。
也就是 事物的范围应该更小
但是,发现事务失效了 (addMediaFilesToDb内添加除零异常)为什么在uploadFile 上加 @Transactional注解就能生效而 addMediaFilesToDb不行呢?
方法拥有事务的能力是因为spring aop生成代理了对象,通过代理对象调用事务方法才能直接生成事务
debug会发现,只有 uploadFile 加注解调用的时 代理对象 的方法, 而 addMediaFilesToDb 加注解 走的不是代理 而是本类(相当于this. 方法 调用)
解决方案:
1、在MediaFileService的实现类中注入自己 (这时 通过注入的对象调用(注入的对象一定是代理对象)),并把调用的函数内调用的整个事务函数提到接口
可能有些人可能会有这样的疑问:这种做法会不会出现循环依赖问题?
答案:不会。
其实spring ioc内部的三级缓存保证了它,不会出现循环依赖问题。
2、通过AopContext.currentProxy()获取代理对象再调用
3、重新创建一个新的service类,里面有事务han’shu(不推荐)在原来的类中 注入新类
功能2:上传视频(断点续传功能实现)
通常视频文件都比较大,所以对于媒资系统上传文件的需求要满足大文件的上传要求。http协议本身对上传文件大小没有限制,但是客户的网络环境质量、电脑硬件环境等参差不齐,如果一个大文件快上传完了网断了没有上传完成,需要客户重新上传,用户体验非常差,所以对于大文件上传的要求最基本的是断点续传。
断点续传:上传过程中,网络断开,重新上传时,从已经断点处继续上传。
总体步骤
文件的断点续传 - 解决方案 文件分块上传
1、(前提)前端检查该大文件信息是否已存在?
前端像媒资服务请求查询要上传的文件是否存在,参数是当前文件的md5值
媒资服务根据文件md5值查询文件系统 文件信息是否已经上传,如果是将不再上传
2、如果分块文件不存在则前端请求媒资开始上传分块(分块是前端完成)
- 前端遍历每一个分块
- 查询当前分块是否存在,不存在则上传,存在则不上传/ 无论是查询还是 上传,都要经过 媒资管理这个中介。
- 上传
3、 上传完毕后,前端请求合并数据 ,媒资完成文件系统内的合并操作
- 合并
- 合并完成校验合并后的文件是否完整(通过下载获取md5 与 当前文件的md5是否一致),如果完整则上传完成,否则删除文件
- 将信息录入到媒资数据库当中
- 入库完成后删除分块文件
4、处理废旧上传分块文件(用户中途穿一半不不传了,以后也不传)
- 解决方案:为媒资文件设定状态(1、上传中途2、上传完毕)设置一个定时器,每隔一段时间如24小时检查上处于上传中途文件的创建事件是否超过了24小时,如果超过就清除分块文件。

所以。完成断电续传这个个功能需要暴露三个接口给前端
1、 检查整体文件 / 检查分块文件
2、上传分块
3、合并分块
热身:文件分块与合并
java 随机流实现
@Test
public void testChunk() throws IOException {
// 1、找到源文件
File sourceFile = new File("E:\\test\\vvefdio\\sss.mp4");
// 将文件分块,分块文件的存储路径
String chunkFilePath = "E:\\test\\vvefdio\\Chunk\\";
// 分块文件的大小
int chunkSize = 1024 *1024 *1 ;// 1MB
// 分块文件的个数
int chunkNum = (int) Math.ceil(sourceFile.length() * 1.0/ chunkSize);
// 填充分块文件(随机流)
RandomAccessFile rand_r = new RandomAccessFile(sourceFile, "r");// 读取源文件
// 缓冲区 用于存储读取的数据
byte[] buffer = new byte[chunkSize];
for(int i=0;i<chunkNum;i++){
File chunkFile = new File(chunkFilePath+i); // 分块文件的 路径、名称
// 分块文件的写入流
RandomAccessFile rand_rw = new RandomAccessFile(chunkFile,"rw");
int len = -1;
while((len=rand_r.read(buffer))!=-1){
rand_rw.write(buffer,0,len); // 把 buffer 里面的内容往 目标晚间里面写
if(chunkFile.length()>=chunkSize){
break;
}
}
rand_rw.close();
}
rand_r.close();
}@Test
public void testMerge() throws IOException {
// 将文件分块,分块文件的存储路径
String chunkFileFolder = "E:\\test\\vvefdio\\Chunk\\";
// 分块文件的大小
int chunkSize = 1024 *1024 *1 ;// 1MB
// 合并文件
File mergeFile = new File("E:\\test\\vvefdio\\sss_merge.mp4");
// 取出所有的分块文件
File[] files_array = new File(chunkFileFolder).listFiles();
List<File> files = Arrays.asList(files_array);
// 按序读取
Collections.sort(files,new Comparator<File>(){
@Override
public int compare(File o1, File o2) {
return Integer.parseInt(o1.getName())-Integer.parseInt(o2.getName());
}
});
// 遍历分块,向合并文件写
RandomAccessFile rand_rw = new RandomAccessFile(mergeFile,"rw");
byte[] buffer = new byte[1024];
for (File file : files) {
// 读取 分块
RandomAccessFile rand_r = new RandomAccessFile(file,"r");
//
int len=-1;
while((len=rand_r.read(buffer))!=-1){
rand_rw.write(buffer,0,len);
}
rand_r.close();
}
rand_rw.close();
// 校验 md5
// 源文件
File soureFile= new File("E:\\test\\vvefdio\\sss.mp4");
InputStream sourceIn = new FileInputStream(soureFile);
String s1=DigestUtils.md5DigestAsHex(sourceIn);
// 合并文件
//File mergeFile= new File("E:\\test\\vvefdio\\sss_merge.mp4");
InputStream mergeIn = new FileInputStream(soureFile);
String s2=DigestUtils.md5DigestAsHex(mergeIn);
Assert.isTrue(s1.equals(s2));
}热身:minio文件合并
合并分块是直接用 minio的提供的SDK接口
minio 上传分块
@Test
public void uploadChunk() throws Exception {
// 分块文件夹
String chunkFilePath = "E:\\test\\vvefdio\\Chunk\\";
//
File[] files = new File(chunkFilePath).listFiles();
for (int i = 0; i < files.length; i++) {
minioClient.uploadObject(
UploadObjectArgs.builder()
.bucket("testbucket")
.object("test/chunkFiles/"+i) // 同一个桶内对象名不能重复
.filename(chunkFilePath+i)
.build()
);
}
}minio文件合并
// 合并文件
@Test
public void testMerge() throws ServerException, InsufficientDataException, ErrorResponseException, IOException, NoSuchAlgorithmException, InvalidKeyException, InvalidResponseException, XmlParserException, InternalException {
// 获取分块文件目录,获取里面的所有应该合并的文件
List<ComposeSource> sources = new ArrayList<>();
for (int i = 0; i < 3; i++) {
ComposeSource composeSource = ComposeSource.builder()
.bucket("testbucket")
.object("test/chunkFiles/" + i)
.build();
sources.add(composeSource);
}
minioClient.composeObject(
ComposeObjectArgs.builder()
.bucket("testbucket")
.sources(sources)
.object("test/mergeFile.mp4") // 合并后的name
.build()
);
// 发现报错IllegalArgumentException: source size 1048576 must be greater than 5242880
// 也就是 minio 默认分块文件大小应该是5MB
} 发现报错IllegalArgumentException: source size 1048576 must be greater than 5242880
也就是 minio 默认分块文件大小应该是5MB
把之前所有分块大小 改为5MB 重来
ok 测试成功
查询(分块)文件时候在MinIO
已经实现过查询文件了
接口定义:
将整个大文件上传要用的接口 定义在 BigFilesController 这个类里面
从课程资料中拷贝RestResponse.java类到base工程下的model包下。
根据之前的讨论,需要暴露四个接口在外面
@Api(value = "大文件上传接口", tags = "大文件上传接口")
@RestController
public class BigFilesController {
@ApiOperation(value = "文件上传前检查文件")
@PostMapping("/upload/checkfile")
public RestResponse<Boolean> checkfile(
@RequestParam("fileMd5") String fileMd5
) throws Exception {
return null;
}
@ApiOperation(value = "分块文件上传前的检测")
@PostMapping("/upload/checkchunk")
public RestResponse<Boolean> checkchunk(@RequestParam("fileMd5") String fileMd5,
@RequestParam("chunk") int chunk) throws Exception {
return null;
}
@ApiOperation(value = "上传分块文件")
@PostMapping("/upload/uploadchunk")
public RestResponse uploadchunk(@RequestParam("file") MultipartFile file,
@RequestParam("fileMd5") String fileMd5,
@RequestParam("chunk") int chunk) throws Exception {
return null;
}
@ApiOperation(value = "合并文件")
@PostMapping("/upload/mergechunks")
public RestResponse mergechunks(@RequestParam("fileMd5") String fileMd5,
@RequestParam("fileName") String fileName,
@RequestParam("chunkTotal") int chunkTotal) throws Exception {
return null;
}
}
接口开发
检查文件和分块
MediaFileService 中定义 检查文件/分块 方法
public RestResponse<Boolean> checkFile(String fileMd5);
public RestResponse<Boolean> checkChunk(String fileMd5, int chunkIndex);实现
// 检查文件
@Override
public RestResponse<Boolean> checkFile(String fileMd5) {
// 数据库查询是否存在?
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if(mediaFiles!=null){
// minio中书否存在?
// 桶
String bucket = mediaFiles.getBucket();
// 存储目录
String filePath = mediaFiles.getFilePath();
InputStream stream = null;
try {
stream = minioClient.getObject(GetObjectArgs.builder()
.bucket(bucket)
.object(filePath)
.build());
if (stream!=null){ //文件已存在
return RestResponse.success(true);
}
} catch (Exception e) {
e.printStackTrace();
}
}
//文件不存在
return RestResponse.success(false);
}
// 查询分块文件是否存在
// 对于整个文件来说可以从minio查询 文件存储的位置,对于分块文件来说,需要自定义分块文件的存储路径,查询的时候也按照哥哥方式来查
// 我们直接以分块文件的前 2位作为一个目录
@Override
public RestResponse<Boolean> checkChunk(String fileMd5, int chunkIndex) {
//得到分块文件目录
String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);
//得到分块文件的路径
String chunkFilePath = chunkFileFolderPath + chunkIndex;
//文件流
InputStream fileInputStream = null;
try {
fileInputStream = minioClient.getObject(
GetObjectArgs.builder()
.bucket(bucket_videoFiles)
.object(chunkFilePath)
.build());
if (fileInputStream != null) {
//分块已存在
return RestResponse.success(true);
}
} catch (Exception e) {
}
//分块未存在
return RestResponse.success(false);
}
//得到分块文件的目录
private String getChunkFileFolderPath(String fileMd5) {
return fileMd5.substring(0, 1) + "/" + fileMd5.substring(1, 2) + "/" + fileMd5 + "/" + "chunk" + "/";
}上传分块文件
service
public RestResponse uploadChunk(String fileMd5,int chunk,byte[] bytes);实现
@Override
public RestResponse uploadChunk(String fileMd5, int chunk, byte[] bytes) {
//得到分块文件的目录路径
String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);
//得到分块文件的路径
String chunkFilePath = chunkFileFolderPath + chunk;
try {
//将文件存储至minIO
addMediaFilesToMinIO(bytes, bucket_videoFiles,chunkFilePath);
return RestResponse.success(true);
} catch (Exception ex) {
ex.printStackTrace();
log.debug("上传分块文件:{},失败:{}",chunkFilePath,e.getMessage());
}
return RestResponse.validfail(false,"上传分块失败");
}
测试
发现直接测试上传视屏会报错
系统异常:
这还是之前的原因:
MinIO限制上传分块的文件大小位5MB
所以在前端把分块大小定为5MB以上(不然就得改MINIO SDK 源码)
- 课程资料前端文件中有一个 uploadtools.ts 文件
- 将其覆盖在前端工程 src/utils 目录下的同名文件中
- 课程资料还有个 .vue 文件 ,将其 覆盖在src/module-organization/pages/media-manage/components/media-add-dialog.vue
- 重启前端服务
发现还是报错
Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.impl.FileSizeLimitExceededException: The field file exceeds its maximum permitted size of 1048576 bytes.
这个错误是后端Springboot导致的
前端对文件分块的大小为5MB,SpringBoot web默认上传文件的大小限制为1MB,这里需要在media-api工程修改配置如下:
spring:
servlet:
multipart:
max-file-size: 50MB
max-request-size: 50MB
测试成功!
合并分块
service
public RestResponse mergechunks(Long companyId,String fileMd5,int chunkTotal,UploadFileParamsDto uploadFileParamsDto);实现
@Override
public RestResponse mergechunks(Long companyId, String fileMd5, int chunkTotal, UploadFileParamsDto uploadFileParamsDto) {
//=====获取分块文件路径=====
String chunkFileFolderPath = getChunkFileFolderPath(fileMd5);
//组成将分块文件路径组成 List<ComposeSource>
List<ComposeSource> sourceObjectList = Stream.iterate(0, i -> ++i)
.limit(chunkTotal)
.map(i -> ComposeSource.builder()
.bucket(bucket_videoFiles)
.object(chunkFileFolderPath.concat(Integer.toString(i)))
.build())
.collect(Collectors.toList());
//=====合并=====
//文件名称
String fileName = uploadFileParamsDto.getFilename();
//文件扩展名
String extName = fileName.substring(fileName.lastIndexOf("."));
//合并文件路径
String mergeFilePath = getFilePathByMd5(fileMd5, extName);
try {
//合并文件
ObjectWriteResponse response = minioClient.composeObject(
ComposeObjectArgs.builder()
.bucket(bucket_videoFiles)
.object(mergeFilePath)
.sources(sourceObjectList)
.build());
log.debug("合并文件成功:{}",mergeFilePath);
} catch (Exception e) {
log.debug("合并文件失败,fileMd5:{},异常:{}",fileMd5,e.getMessage(),e);
return RestResponse.validfail(false, "合并文件失败。");
}
// ====验证md5====
File minioFile = downloadFileFromMinIO(bucket_videoFiles,mergeFilePath);
if(minioFile == null){
log.debug("下载合并后文件失败,mergeFilePath:{}",mergeFilePath);
return RestResponse.validfail(false, "下载合并后文件失败。");
}
try (InputStream newFileInputStream = new FileInputStream(minioFile)) {
//minio上文件的md5值
String md5Hex = DigestUtils.md5Hex(newFileInputStream);
//比较md5值,不一致则说明文件不完整
if(!fileMd5.equals(md5Hex)){
return RestResponse.validfail(false, "文件合并校验失败,最终上传失败。");
}
//文件大小
uploadFileParamsDto.setFileSize(minioFile.length());
}catch (Exception e){
log.debug("校验文件失败,fileMd5:{},异常:{}",fileMd5,e.getMessage(),e);
return RestResponse.validfail(false, "文件合并校验失败,最终上传失败。");
}finally {
if(minioFile!=null){
minioFile.delete();
}
}
//文件入库
currentProxy.addMediaFilesToDb(companyId,fileMd5,uploadFileParamsDto,bucket_videoFiles,mergeFilePath);
//=====清除分块文件=====
clearChunkFiles(chunkFileFolderPath,chunkTotal);
return RestResponse.success(true);
}
/**
* 从minio下载文件
* @param bucket 桶
* @param objectName 对象名称
* @return 下载后的文件
*/
public File downloadFileFromMinIO(String bucket,String objectName){
//临时文件
File minioFile = null;
FileOutputStream outputStream = null;
try{
InputStream stream = minioClient.getObject(GetObjectArgs.builder()
.bucket(bucket)
.object(objectName)
.build());
//创建临时文件
minioFile=File.createTempFile("minio", ".merge");
outputStream = new FileOutputStream(minioFile);
IOUtils.copy(stream,outputStream);
return minioFile;
} catch (Exception e) {
e.printStackTrace();
}finally {
if(outputStream!=null){
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
/**
* 得到合并后的文件的地址
* @param fileMd5 文件id即md5值
* @param fileExt 文件扩展名
* @return
*/
private String getFilePathByMd5(String fileMd5,String fileExt){
return fileMd5.substring(0,1) + "/" + fileMd5.substring(1,2) + "/" + fileMd5 + "/" +fileMd5 +fileExt;
}
/**
* 清除分块文件
* @param chunkFileFolderPath 分块文件路径
* @param chunkTotal 分块文件总数
*/
private void clearChunkFiles(String chunkFileFolderPath,int chunkTotal){
try {
List<DeleteObject> deleteObjects = Stream.iterate(0, i -> ++i)
.limit(chunkTotal)
.map(i -> new DeleteObject(chunkFileFolderPath.concat(Integer.toString(i))))
.collect(Collectors.toList());
RemoveObjectsArgs removeObjectsArgs = RemoveObjectsArgs.builder().bucket("video").objects(deleteObjects).build();
Iterable<Result<DeleteError>> results = minioClient.removeObjects(removeObjectsArgs);
results.forEach(r->{
DeleteError deleteError = null;
try {
deleteError = r.get();
} catch (Exception e) {
e.printStackTrace();
log.error("清楚分块文件失败,objectname:{}",deleteError.objectName(),e);
}
});
} catch (Exception e) {
e.printStackTrace();
log.error("清楚分块文件失败,chunkFileFolderPath:{}",chunkFileFolderPath,e);
}
}
接口完善
@ApiOperation(value = "合并文件")
@PostMapping("/upload/mergechunks")
public RestResponse mergechunks(@RequestParam("fileMd5") String fileMd5,
@RequestParam("fileName") String fileName,
@RequestParam("chunkTotal") int chunkTotal) throws Exception {
Long companyId = 1232141425L;
UploadFileParamsDto uploadFileParamsDto = new UploadFileParamsDto();
uploadFileParamsDto.setFileType("001002");
uploadFileParamsDto.setTags("课程视频");
uploadFileParamsDto.setRemark("");
uploadFileParamsDto.setFilename(fileName);
return mediaFileService.mergechunks(companyId,fileMd5,chunkTotal,uploadFileParamsDto);
}
测试


成功!
功能3 :文件预览

预览的方式是通过浏览器直接打开文件,对于图片和浏览器支持的视频格式可以直接浏览
本质上就是返回资源文件的url给前端
接口定义
@ApiOperation(value = "预览文件")
@GetMapping("/preview/{mediaId}")
public RestResponse<String> getPlayUrlByMediaId(@PathVariable String mediaId) {
return null;
}接口开发
设置URL
- 有一些浏览器不支持的视频格式,不能在浏览器中直接浏览,所以我们要修改保存媒资信息到数据库的方法
- 当文件是图片时,设置URL字段
- 当视频是MP4格式时,设置URL字段
- 其他情况暂不设置URL,需要文件处理后再设置URL字段
这就需要我们在原来的添加文件信息到数据库的那段代码里面做些修改了
/**
* 将文件信息添加到文件表
*
* @param companyId 机构id
* @param uploadFileParamsDto 上传文件的信息
* @param objectName 对象名称
* @param fileMD5 文件的md5码
* @param bucket 桶
*/
@Transactional
public MediaFiles addMediaFilesToDB(Long companyId, UploadFileParamsDto uploadFileParamsDto, String objectName, String fileMD5, String bucket) {
// 保存到数据库
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMD5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMD5);
mediaFiles.setFileId(fileMD5);
mediaFiles.setCompanyId(companyId);
mediaFiles.setBucket(bucket);
mediaFiles.setCreateDate(LocalDateTime.now());
mediaFiles.setStatus("1");
mediaFiles.setFilePath(objectName);
+ // 获取源文件名的contentType
+ String contentType = getContentType(objectName);
+ // 如果是图片格式或者mp4格式,则设置URL属性,否则不设置
+ if (contentType.contains("image") || contentType.contains("mp4")) {
+ mediaFiles.setUrl("/" + bucket + "/" + objectName);
+ }
// 查阅数据字典,002003表示审核通过
mediaFiles.setAuditStatus("002003");
}
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert <= 0) {
XueChengPlusException.cast("保存文件信息失败");
}
return mediaFiles;
}Service开发
MediaFiles getFileById(String mediaId);@Override
public MediaFiles getFileById(String id) {
MediaFiles mediaFiles = mediaFilesMapper.selectById(id);
if (mediaFiles == null || StringUtils.isEmpty(mediaFiles.getUrl())) {
XueChengPlusException.cast("视频还没有转码处理");
}
return mediaFiles;
}接口
@ApiOperation(value = "预览文件")
@GetMapping("/preview/{mediaId}")
public RestResponse<String> getPlayUrlByMediaId(@PathVariable String mediaId) {
MediaFiles mediaFile = mediaFileService.getFileById(mediaId);
return RestResponse.success(mediaFile.getUrl());
}功能4:视频处理(视频转码)
为什么要转码?视频是每个课程必须有的,转码方便后续统一处理
首先我们要分清文件格式和编码格式:
文件格式,可以理解为后缀名扩展名,.mp4、.avi、.rmvb
编码格式,可以理解为具体的编码算法,对于一个视频文件来说,其音视频编码格式 包括 视频编码 和 音频编码 两部分
音视频编码格式系列
1、MPEG系列
2、H.26X系列
需求:我们将文件格式统一转为mp4,视频编码统一转为H.264,音频AAC。
前提:
转码具体算法以及工具我们直接调用 FFmpeg,我们直接调用即可,主要是使用程序自动调用,转换。
下载 ffmpeg
可以将ffmpeg.exe配置到环境变量path中,进入视频目录直接运行:ffmpeg.exe -i 1.avi 1.mp4
转成mp3:ffmpeg -i nacos.avi nacos.mp3
转成gif:ffmpeg -i nacos.avi nacos.gif
将课程资料目录中的util.zip解压,将解压出的工具类拷贝至base工程。
其中Mp4VideoUtil类是用于将视频转为mp4格式,是我们项目要使用的工具类。
下边看下这个类的代码,并进行测试。
工具类测试
public static void main(String[] args) throws IOException {
//ffmpeg的路径
String ffmpeg_path = "E:\\software\\FFmpeg\\ffmpeg.exe";//ffmpeg的安装位置
//源avi视频的路径
String video_path = "E:\\test\\vvefdio\\sss.avi";
//转换后mp4文件的名称
String mp4_name = "sss_mp4.mp4";
//转换后mp4文件的路径
String mp4_path = "E:\\test\\vvefdio\\sss_mp4.mp4";
//创建工具类对象
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpeg_path,video_path,mp4_name,mp4_path);
//开始视频转换,成功将返回success
String s = videoUtil.generateMp4();
System.out.println(s);
}
批量转码(分布式任务调度)
什么是分布式任务调度?
一个视频转码相当于一个任务,转码是一个耗时的工作
假如用户量多了,如何面对大量的转码任务?分布式任务调度
如何高效处理任务? 多线程,但是单机运行能力有限,多个机器处理 -》 多个机器(服务实例)加多线程
问题:(分布式) 如何 分配这些任务到各个机器的各个线程,(调度)又如何控制 任务开始时间 这就是分布式任务调度(分配一级时间)。
常用于以下场景:
- 每隔24小时数据备份
- 12306 每个一段时间放票
- 商品发货成功后,向客户发送信息提醒
根据CAP理论,更看重一致性的场景,对及时性(可用性)要求不高
单机下 任务调度的实现方式
发现基本都是定时、定间隔任务,简单情况可以使用 1、while(true )+sleep 2、 Timer 和 3、 ScheduledExecutor 方案实现,但是对于复杂场景实现困难,如每一个月的固定时间?等等 还有一些第三放框架
第三方Quartz方式实现
Quartz 是一个功能强大的任务调度框架,它可以满足更多更复杂的调度需求,Quartz 设计的核心类包括 Scheduler, Job 以及 Trigger。其中,Job 负责定义需要执行的任务,Trigger 负责设置调度策略,Scheduler 将二者组装在一起,并触发任务开始执行。Quartz支持简单的按时间间隔调度、还支持按日历调度方式,通过设置CronTrigger表达式(包括:秒、分、时、日、月、周、年)进行任务调度。
如:
public static void main(String [] agrs) throws SchedulerException {
//创建一个Scheduler
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
Scheduler scheduler = schedulerFactory.getScheduler();
//创建JobDetail
JobBuilder jobDetailBuilder = JobBuilder.newJob(MyJob.class);
jobDetailBuilder.withIdentity("jobName","jobGroupName");
JobDetail jobDetail = jobDetailBuilder.build();
//创建触发的CronTrigger 支持按日历调度
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity("triggerName", "triggerGroupName")
.startNow()
.withSchedule(CronScheduleBuilder.cronSchedule("0/2 * * * * ?"))
.build();
scheduler.scheduleJob(jobDetail,trigger);
scheduler.start();
}
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext jobExecutionContext){
System.out.println("todo something");
}
}
以上单机方式一定无法满足 计算量 可用性的需求,分布式任务调度的要求更高,如下,单机无法满足。
分布式任务调度的目标
1、并行任务调度
2、高可用(失败重试)、弹性扩容
3、任务管理与监测
4、避免任务重复执行
分布式任务调度中间件- xxl -job
他是一个中间件(软件)
主要由 调度中心(管理者)、执行器(分布式部署)、任务 组成

流程
1.任务执行器根据配置的调度中心的地址,自动注册到调度中心
2.达到任务触发条件,调度中心下发任务
3.执行器基于线程池执行任务,并把执行结果放入内存队列中、把执行日志写入日志文件中
4.执行器消费内存队列中的执行结果,主动上报给调度中心
5.当用户在调度中心查看任务日志,调度中心请求任务执行器,任务执行器读取任务日志文件并返回日志详情
搭建XXL-JOB
首先根据上面的介绍,需要明确,主要就是分 调度中心和 执行器 ,xxl job 作为 一个“外部中间件”
- 使用IDEA打开项目
- xxl-job-admin:调度中心
- xxl-job-core:公共依赖
- xxj-job-executor-samples:执行器Sample示例
- xxl-job-executor-sample-springboot:SpringBoot版本,通过SpringBoot管理执行器
- xxl-job-executor-sample-frameless:无框架版本
根据数据库脚本创建数据库,修改数据库连接信息和端口,启动xxl-job-admin,访问http://local:18088/xxl-job-admin/
admin/123456

配置调度中心(部署到linux)
将项目打包,放到linux上

nohup java -jar /绝对路径/xxl-job-admin-2.3.1.jar &
nohup java -jar /usr/local/myjp/xxl-job-admin-2.3.1.jar &
成功!
执行器是部署在微服务(实例)中的
配置执行器
下面配置执行器,执行器负责与调度中心通信,接收调度中心发起的任务调度请求
1、配置:首先在media-service工程中添加依赖(父工程中完成了版本控制,这里的版本是2.3.1)
<dependency>
<groupId>com.xuxueli</groupId>
<artifactId>xxl-job-core</artifactId>
</dependency>2、将执行器服务上报给xxl job,那么在 nacos 配置中心中 对 media-service-dev.yaml 添加配置
xxl:
job:
admin:
addresses: http://192.168.101.65:18088/xxl-job-admin
executor:
appname: media-process-service
address:
ip:
port: 9999
logpath: /data/applogs/xxl-job/jobhandler
logretentiondays: 30
accessToken: default_token3、配置xxl-job的执行器配置类,放在 service config中
@Configuration
public class XxlJobConfig {
private Logger logger = LoggerFactory.getLogger(XxlJobConfig.class);
@Value("${xxl.job.admin.addresses}")
private String adminAddresses;
@Value("${xxl.job.accessToken}")
private String accessToken;
@Value("${xxl.job.executor.appname}")
private String appname;
@Value("${xxl.job.executor.address}")
private String address;
@Value("${xxl.job.executor.ip}")
private String ip;
@Value("${xxl.job.executor.port}")
private int port;
@Value("${xxl.job.executor.logpath}")
private String logPath;
@Value("${xxl.job.executor.logretentiondays}")
private int logRetentionDays;
@Bean
public XxlJobSpringExecutor xxlJobExecutor() {
logger.info(">>>>>>>>>>> xxl-job config init.");
XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor();
xxlJobSpringExecutor.setAdminAddresses(adminAddresses);
xxlJobSpringExecutor.setAppname(appname);
xxlJobSpringExecutor.setAddress(address);
xxlJobSpringExecutor.setIp(ip);
xxlJobSpringExecutor.setPort(port);
xxlJobSpringExecutor.setAccessToken(accessToken);
xxlJobSpringExecutor.setLogPath(logPath);
xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays);
return xxlJobSpringExecutor;
}
/**
* 针对多网卡、容器内部署等情况,可借助 "spring-cloud-commons" 提供的 "InetUtils" 组件灵活定制注册IP;
*
* 1、引入依赖:
* <dependency>
* <groupId>org.springframework.cloud</groupId>
* <artifactId>spring-cloud-commons</artifactId>
* <version>${version}</version>
* </dependency>
*
* 2、配置文件,或者容器启动变量
* spring.cloud.inetutils.preferred-networks: 'xxx.xxx.xxx.'
*
* 3、获取IP
* String ip_ = inetUtils.findFirstNonLoopbackHostInfo().getIpAddress();
*/
}4、进入调度中心,添加执行器
如,我们要添加一个media-process-service 的执行器;(因为刚才我们在配置文件里面就是写的那个appName)

5、重启媒资管理服务模块,可以看到执行器在调入中心注册成功
报错:
Could not resolve placeholder ‘xxl.job.executor.address’ in value “${xxl.job.executor.address}”、
emmm 发现解析不了,干脆删除得了 (注意把配置文件一级配置类里面的 address 以及 ip 相关语句全部注释掉)
最后发现成功,就是这里的ip比较纳闷。

执行任务
下边编写任务,参考示例工程中任务类的编写方法
在媒资服务service包下新建jobhandler存放任务类,下边参考示例工程编写一个任务类
package com.xxl.job.executor.service.jobhandler;
@Component
@Slf4j
public class SampleJob {
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("testJob")
public void testJob() throws Exception {
log.info("开始执行.....");
}
}在调度中心分配任务
在调度中心新建任务
选定执行器

CRON表达式:
- 每隔三秒执行一次

- 每隔10分钟执行一次
1、取消每秒

2、选分钟设置

3、每天的 1点0分0秒
指定小时

指定分钟

指定秒

现在设置每5秒执行一次
0/5 ?
设置任务名称,@XxlJob(“testJob”) 中的 “testJob” 将其复制在下面

其他的不用配置
启动任务

可以看到任务成功启动

高级配置
路由策略
我们最常见的就是路由策略就是 固定、轮询、一致性哈希、随机 这五种

第一个/ 最后一个:(固定)
轮询:
随机:
一致性哈希:
- 普通哈希: 哈希值取模:缺点当模的数量改变时,前面的那些 全部失效,需要重新计算模值
- 一致性哈希:构成一个hash环,服务器(映射到环上)将其分段、 再讲任务映射到环上,当增加或减少服务器时是由一部分需要重新映射见下图

这里只有任务3需要重新映射,其他的都不需要重新映射
调度过期策略

忽略,如果上次调度没成功/过期,执行器的动作
阻塞策略(相当于线程池的拒绝策略)

单机串型:暂时阻塞住
丢弃后续:被阻塞的丢弃
覆盖: 停止当前,调用当前
文档:
高级配置:
- 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
FIRST(第一个):固定选择第一个机器;
LAST(最后一个):固定选择最后一个机器;
ROUND(轮询):;
RANDOM(随机):随机选择在线的机器;
CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度,通过子任务可以实现一个任务执行完成去执行另一个任务。
- 调度过期策略:
- 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
- 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
- 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
- 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;分片广播
下边要重点说的是分片广播策略,分片是指是调度中心以执行器为维度进行分片,将集群中的执行器标上序号:0,1,2,3…,广播是指每次调度会向集群中的所有执行器发送任务调度,请求中携带分片参数。

每个执行器收到调度请求同时接收分片参数。
xxl-job支持动态扩容执行器集群从而动态增加分片数量,当有任务量增加可以部署更多的执行器到集群中,调度中心会动态修改分片的数量。
作业分片适用哪些场景呢?
• 分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
• 广播任务场景:广播执行器同时运行shell脚本、广播集群节点进行缓存更新等。
所以,广播分片方式不仅可以充分发挥每个执行器的能力,并且根据分片参数可以控制任务是否执行,最终灵活控制了执行器集群分布式处理任务。
Java语言任务获取分片参数方式:
BEAN、GLUE模式(Java),可参考Sample示例执行器中的示例任务
下边测试作业分片:
1、定义作业分片的任务方法
/**
* 2、分片广播任务
*/
@XxlJob("shardingJobHandler")
public void shardingJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
log.info("分片参数:当前分片序号 = {}, 总分片数 = {}", shardIndex, shardTotal);
log.info("开始执行第"+shardIndex+"批任务");
}
2、 开启多个实例 注意在配置文件中设置本地优先
# 配置本地优先
cloud:
config:
override-none: true-Dserver.port=63051 -Dxxl.job.executor.port=9998
-Dserver.port=63052 -Dxxl.job.executor.port=99973、查看执行器是否注册到xxljob

4、 调度任务

5、查看

保证任务不重复执行(一个任务分一个执行器)
调度中心给每一个执行器分一个分片序号
任务 有不同的 id
方案: 求余 用任务的编号 id 除以 分片总数 求余 ,余数等于几就给对应的执行器执行
保证不重复执行的方式:
1、分配:调度器按照分片广播的方式调度执行器,每个执行器只有唯一的分片号。保证一个任务只分配到一个 执行器 :求余
2、过期策略: 选择 忽略,过期了就忽略- 下次不过期再执行
3、阻塞处理策略:丢弃后续调度或单机串行方式 不要选择覆盖执行即可
4、任务的处理的幂等性(处理完设置状态/乐观锁):一次请求和多次请求应该有同样的结果(解决重复支付、恶意刷单)
任务的幂等性如何保证?避免重复提交插入多条等i情况
1、数据库约束,通过唯一索引提交,只有一次提交成功
2、乐观锁: 版本号,只有版本号/状态对了才能进入,进入更改版本号
3、序列号:如 订单号, 一个订单生成时会附带一个token给用户,同时在内存(redis)中记录 token ,用户提交订单时,会将token id 再发给客户端,服务端清理 token并处理任务。 如果客户重复下单,服务器查询内存中是否存在,只有不存在的才会处理。
视频处理整体流程

所以再 上传数据库那里,上传完视频,要把要转码的视频 添加到一个转码任务表中。
转码流程如下

1、任务调度中心广播作业分片。
2、执行器收到广播作业分片,从数据库读取待处理任务,读取未处理及处理失败的任务。
3、执行器更新任务为处理中,根据任务内容从MinIO下载要处理的文件。
4、执行器启动多线程去处理任务。
5、任务处理完成,上传处理后的视频到MinIO。
6、将更新任务处理结果,如果视频处理完成除了更新任务处理结果以外还要将文件的访问地址更新至任务处理表及文件表中,最后将任务完成记录写入历史表。
步骤1:上传视频时添加任务
上传视频成功向视频处理待处理表添加记录,暂时只添加对avi视频的处理记录。
根据MIME Type去判断是否是avi视频,下边列出部分MIME Type

@Transactional
public MediaFiles addMediaFilesToDb(Long companyId,String fileMd5,UploadFileParamsDto uploadFileParamsDto,String bucket,String objectName){
//从数据库查询文件
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileMd5);
if (mediaFiles == null) {
mediaFiles = new MediaFiles();
//拷贝基本信息
BeanUtils.copyProperties(uploadFileParamsDto, mediaFiles);
mediaFiles.setId(fileMd5);
mediaFiles.setFileId(fileMd5);
mediaFiles.setCompanyId(companyId);
mediaFiles.setUrl("/" + bucket + "/" + objectName);
mediaFiles.setBucket(bucket);
mediaFiles.setFilePath(objectName);
mediaFiles.setCreateDate(LocalDateTime.now());
mediaFiles.setAuditStatus("002003");
mediaFiles.setStatus("1");
// 获取源文件名的contentType
String contentType = getMimeType(objectName);
// 如果是图片格式或者mp4格式,则设置URL属性,否则不设置
if (contentType.contains("image") || contentType.contains("mp4")) {
mediaFiles.setUrl("/" + bucket + "/" + objectName);
}
//保存文件信息到文件表
int insert = mediaFilesMapper.insert(mediaFiles);
if (insert < 0) {
log.error("保存文件信息到数据库失败,{}",mediaFiles.toString());
XuechengPlusException.cast("保存文件信息失败");
}
+ // 如果是avi视频,则额外添加至视频待处理表
+ if ("video/x-msvideo".equals(contentType)) {
+ MediaProcess mediaProcess = new MediaProcess();
+ BeanUtils.copyProperties(mediaFiles, mediaProcess);
+ mediaProcess.setStatus("1"); // 未处理
+ int processInsert = mediaProcessMapper.insert(mediaProcess);
+ if (processInsert <= 0) {
+ XuechengPlusException.cast("保存avi视频到待处理表失败");
+ }
+ }
log.debug("保存文件信息到数据库成功,{}",mediaFiles.toString());
}
return mediaFiles;
}步骤2: 查询待处理任务
如何保证查询到的待处理视频记录不重复?
select * from 任务处理表 where 任务id%分片总数 = 分片id and 状态位未处理或者处理实拍 and 重复次数<3 limit 线程数
Mapper
public interface MediaProcessMapper extends BaseMapper<MediaProcess> {
/**
* @description 根据分片参数获取待处理任务
* @param shardTotal 分片总数
* @param shardindex 分片序号
* @param count 任务数
* @return java.util.List<com.xuecheng.media.model.po.MediaProcess>
* @date 2022/9/14 8:54
*/
@Select("select * from media_process t where t.id % #{shardTotal} = #{shardIndex} and (t.status = '1' or t.status = '3') and t.fail_count < 3 limit #{count}")
List<MediaProcess> selectListByShardIndex(@Param("shardTotal") int shardTotal,@Param("shardIndex") int shardIndex,@Param("count") int count);
}
service
public interface MediaFileProcessService {
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count);
}service接口实现
package com.xuecheng.media.service.impl;
@Slf4j
@Service
public class MediaFileProcessServiceImpl implements MediaFileProcessService {
@Autowired
MediaFilesMapper mediaFilesMapper;
@Autowired
MediaProcessMapper mediaProcessMapper;
@Override
public List<MediaProcess> getMediaProcessList(int shardIndex, int shardTotal, int count) {
List<MediaProcess> mediaProcesses = mediaProcessMapper.selectListByShardIndex(shardTotal, shardIndex, count);
return mediaProcesses;
}
}
步骤3:实现分布式锁
如果是多个执行器分布式部署,并不能保证同一个视频只有一个执行器去处理。所以使用分布式锁
分布式锁的实现方式
实现分布式锁的方案有很多,常用的如下:
1、基于数据库实现分布锁
利用数据库主键唯一性的特点,或利用数据库唯一索引、行级锁的特点,多个线程同时去更新相同的记录,谁更新成功谁就抢到锁。
2、基于redis实现锁
redis提供了分布式锁的实现方案,比如:SETNX、set nx、redisson等。
拿SETNX举例说明,SETNX命令的工作过程是去set一个不存在的key,多个线程去设置同一个key只会有一个线程设置成功,设置成功的的线程拿到锁。
3、使用zookeeper实现
zookeeper是一个分布式协调服务,主要解决分布式程序之间的同步的问题。zookeeper的结构类似的文件目录,多线程向zookeeper创建一个子目录(节点)只会有一个创建成功,利用此特点可以实现分布式锁,谁创建该结点成功谁就获得锁
我们这里选择第一种方式
用更新数据库唯一索引的语句
update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=?如果是多个线程去执行该sql都将会执行成功,但需求是只能有一个线程抢到锁,所以此sql无法满足需求。
仔细想想这其实是一种CAS乐观锁
1、mapper
/**
* 开启一个任务
* @param id 任务id
* @return 更新记录数
*/
@Update("update media_process m set m.status='4' where (m.status='1' or m.status='3') and m.fail_count<3 and m.id=#{id}")
int startTask(@Param("id") long id);
2、service方法
/**
* 开启一个任务
* @param id 任务id
* @return true开启任务成功,false开启任务失败
*/
public boolean startTask(long id);
3实现
//实现如下
public boolean startTask(long id) {
int result = mediaProcessMapper.startTask(id);
return result<=0?false:true;
}步骤4:更新任务状态
任务结束需要更新任务状态在MediaFileProcessService接口添加方法
void saveProcessFinishStatus(Long taskId,String status,String fileId,String url,String errorMsg);
@Transactional
@Override
public void saveProcessFinishStatus(Long taskId, String status, String fileId, String url, String errorMsg) {
//查出任务,如果不存在则直接返回
MediaProcess mediaProcess = mediaProcessMapper.selectById(taskId);
if(mediaProcess == null){
return ;
}
//处理失败,更新任务处理结果
LambdaQueryWrapper<MediaProcess> queryWrapperById = new LambdaQueryWrapper<MediaProcess>().eq(MediaProcess::getId, taskId);
//处理失败
if(status.equals("3")){
MediaProcess mediaProcess_u = new MediaProcess();
mediaProcess_u.setStatus("3");
mediaProcess_u.setErrormsg(errorMsg);
mediaProcess_u.setFailCount(mediaProcess.getFailCount()+1);
mediaProcessMapper.update(mediaProcess_u,queryWrapperById);
log.debug("更新任务处理状态为失败,任务信息:{}",mediaProcess_u);
return ;
}
//任务处理成功
MediaFiles mediaFiles = mediaFilesMapper.selectById(fileId);
if(mediaFiles!=null){
//更新媒资文件中的访问url
mediaFiles.setUrl(url);
mediaFilesMapper.updateById(mediaFiles);
}
//处理成功,更新url和状态
mediaProcess.setUrl(url);
mediaProcess.setStatus("2");
mediaProcess.setFinishDate(LocalDateTime.now());
mediaProcessMapper.updateById(mediaProcess);
//添加到历史记录
MediaProcessHistory mediaProcessHistory = new MediaProcessHistory();
BeanUtils.copyProperties(mediaProcess, mediaProcessHistory);
mediaProcessHistoryMapper.insert(mediaProcessHistory);
//删除mediaProcess
mediaProcessMapper.deleteById(mediaProcess.getId());
}
步骤5:任务(处理视频)
视频采用并发处理,每个视频使用一个线程去处理,每次处理的视频数量不要超过cpu核心数。
所有视频处理完成结束本次执行,为防止代码异常出现无限期等待则添加超时设置,到达超时时间还没有处理完成仍结束任务。
在之前的jobhander包下创建执行器类,里面编写 对应的视频处理方法
@Slf4j
@Component
public class VideoTask {
@Autowired
MediaFileService mediaFileService;
@Autowired
MediaFileProcessService mediaFileProcessService;
@Value("${videoprocess.ffmpegpath}")
String ffmpegpath;
@XxlJob("videoJobHandler")
public void videoJobHandler() throws Exception {
// 分片参数
int shardIndex = XxlJobHelper.getShardIndex();
int shardTotal = XxlJobHelper.getShardTotal();
List<MediaProcess> mediaProcessList = null;
int size = 0;
try {
//取出cpu核心数作为一次处理数据的条数
// int processors = Runtime.getRuntime().availableProcessors();
int processors=1;
//一次处理视频数量不要超过cpu核心数
mediaProcessList = mediaFileProcessService.getMediaProcessList(shardIndex, shardTotal, processors);
size = mediaProcessList.size();
log.debug("取出待处理视频任务{}条", size);
if (size < 0) {
return;
}
} catch (Exception e) {
e.printStackTrace();
return;
}
//启动size个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(size);
//计数器
CountDownLatch countDownLatch = new CountDownLatch(size);
//将处理任务加入线程池
mediaProcessList.forEach(mediaProcess -> {
threadPool.execute(() -> {
try {
//任务id
Long taskId = mediaProcess.getId();
//抢占任务
boolean b = mediaFileProcessService.startTask(taskId);
if (!b) {
return;
}
log.debug("开始执行任务:{}", mediaProcess);
//下边是处理逻辑
//桶
String bucket = mediaProcess.getBucket();
//存储路径
String filePath = mediaProcess.getFilePath();
//原始视频的md5值
String fileId = mediaProcess.getFileId();
//原始文件名称
String filename = mediaProcess.getFilename();
//将要处理的文件下载到服务器上
File originalFile = mediaFileService.downloadFileFromMinIO(mediaProcess.getBucket(), mediaProcess.getFilePath());
if (originalFile == null) {
log.debug("下载待处理文件失败,originalFile:{}", mediaProcess.getBucket().concat(mediaProcess.getFilePath()));
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "下载待处理文件失败");
return;
}
//处理结束的视频文件
File mp4File = null;
try {
mp4File = File.createTempFile("mp4", ".mp4");
} catch (IOException e) {
log.error("创建mp4临时文件失败");
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "创建mp4临时文件失败");
return;
}
//视频处理结果
String result = "";
try {
//开始处理视频
Mp4VideoUtil videoUtil = new Mp4VideoUtil(ffmpegpath, originalFile.getAbsolutePath(), mp4File.getName(), mp4File.getAbsolutePath());
//开始视频转换,成功将返回success
result = videoUtil.generateMp4();
} catch (Exception e) {
e.printStackTrace();
log.error("处理视频文件:{},出错:{}", mediaProcess.getFilePath(), e.getMessage());
}
if (!result.equals("success")) {
//记录错误信息
log.error("处理视频失败,视频地址:{},错误信息:{}", bucket + filePath, result);
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, result);
return;
}
//将mp4上传至minio
//mp4在minio的存储路径
String objectName = getFilePath(fileId, ".mp4");
//访问url
String url = "/" + bucket + "/" + objectName;
try {
mediaFileService.addMediaFilesToMinIO(mp4File.getAbsolutePath(), "video/mp4", bucket, objectName);
//将url存储至数据,并更新状态为成功,并将待处理视频记录删除存入历史
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "2", fileId, url, null);
} catch (Exception e) {
log.error("上传视频失败或入库失败,视频地址:{},错误信息:{}", bucket + objectName, e.getMessage());
//最终还是失败了
mediaFileProcessService.saveProcessFinishStatus(mediaProcess.getId(), "3", fileId, null, "处理后视频上传或入库失败");
}
}finally {
countDownLatch.countDown();
}
});
});
//等待,给一个充裕的超时时间,防止无限等待,到达超时时间还没有处理完成则结束任务
countDownLatch.await(30, TimeUnit.MINUTES);
}
private String getFilePath(String fileMd5,String fileExt){
return fileMd5.substring(0,1) + "/" + fileMd5.substring(1,2) + "/" + fileMd5 + "/" +fileMd5 +fileExt;
}
}
测试


处理中

处理后



1、xxl-job的工作原理是什么? xxl-job是什么怎么工作?
XXL-JOB分布式任务调度服务由调用中心和执行器组成,调用中心负责按任务调度策略向执行器下发任务,执行器负责接收任务执行任务。
1)首先部署并启动xxl-job调度中心。(一个java工程)
2)首先在微服务添加xxl-job依赖,在微服务中配置执行器
3)启动微服务,执行器向调度中心上报自己。
4)在微服务中写一个任务方法并用xxl-job的注解去标记执行任务的方法名称。
5)在调度中心配置任务调度策略,调度策略就是每隔多长时间执行还是在每天或每月的固定时间去执行,比如每天0点执行,或每隔1小时执行一次等。
6)在调度中心启动任务。
7))调度中心根据任务调度策略,到达时间就开始下发任务给执行器。8)执行器收到任务就开始执行任务。
功能 5:绑定媒资


在内容管理模块定义请求参数模型类型:
@Data
@ApiModel(value="BindTeachplanMediaDto", description="教学计划-媒资绑定提交数据")
public class BindTeachplanMediaDto {
@ApiModelProperty(value = "媒资文件id", required = true)
private String mediaId;
@ApiModelProperty(value = "媒资文件名称", required = true)
private String fileName;
@ApiModelProperty(value = "课程计划标识", required = true)
private Long teachplanId;
}
接口定义
@ApiOperation(value = "课程计划和媒资信息绑定")
@PostMapping("/teachplan/association/media")
public void associationMedia(@RequestBody BindTeachplanMediaDto bindTeachplanMediaDto){
}接口开发
service
public TeachplanMedia associationMedia(BindTeachplanMediaDto bindTeachplanMediaDto);serviceImpl
@Transactional
@Override
public TeachplanMedia associationMedia(BindTeachplanMediaDto bindTeachplanMediaDto) {
//教学计划id
Long teachplanId = bindTeachplanMediaDto.getTeachplanId();
Teachplan teachplan = teachplanMapper.selectById(teachplanId);
if(teachplan==null){
XueChengPlusException.cast("教学计划不存在");
}
Integer grade = teachplan.getGrade();
if(grade!=2){
XueChengPlusException.cast("只允许第二级教学计划绑定媒资文件");
}
//课程id
Long courseId = teachplan.getCourseId();
//先删除原来该教学计划绑定的媒资
teachplanMediaMapper.delete(new LambdaQueryWrapper<TeachplanMedia>().eq(TeachplanMedia::getTeachplanId,teachplanId));
//再添加教学计划与媒资的绑定关系
TeachplanMedia teachplanMedia = new TeachplanMedia();
teachplanMedia.setCourseId(courseId);
teachplanMedia.setTeachplanId(teachplanId);
teachplanMedia.setMediaFilename(bindTeachplanMediaDto.getFileName());
teachplanMedia.setMediaId(bindTeachplanMediaDto.getMediaId());
teachplanMedia.setCreateDate(LocalDateTime.now());
teachplanMediaMapper.insert(teachplanMedia);
return teachplanMedia;
}接口完善
@ApiOperation(value = "课程计划和媒资信息绑定")
@PostMapping("/teachplan/association/media")
void associationMedia(@RequestBody BindTeachplanMediaDto bindTeachplanMediaDto){
teachplanService.associationMedia(bindTeachplanMediaDto);
}
测试成功

功能6:解除绑定
delete /teachplan/association/media/{teachPlanId}/{mediaId}接口定义
@ApiOperation("课程计划解除媒资信息绑定")
@DeleteMapping("/teachplan/association/media/{teachPlanId}/{mediaId}")
public void unassociationMedia(@PathVariable Long teachPlanId, @PathVariable Long mediaId) {
}service
/** 解绑教学计划与媒资信息
* @param teachPlanId 教学计划id
* @param mediaId 媒资信息id
*/
void unassociationMedia(Long teachPlanId, Long mediaId);接口实现
@Override
public void unassociationMedia(Long teachPlanId, Long mediaId) {
LambdaQueryWrapper<TeachplanMedia> queryWrapper = new LambdaQueryWrapper<>();
queryWrapper.eq(TeachplanMedia::getTeachplanId, teachPlanId)
.eq(TeachplanMedia::getMediaId, mediaId);
teachplanMediaMapper.delete(queryWrapper);
}完善
@ApiOperation("课程计划解除媒资信息绑定")
@DeleteMapping("/teachplan/association/media/{teachPlanId}/{mediaId}")
public void unassociationMedia(@PathVariable Long teachPlanId, @PathVariable String mediaId) {
teachplanService.unassociationMedia(teachPlanId, mediaId);
}发现报错,
这不关我的事了吧没传过来居然是null ,我怎么搞?

完毕




